|
| 1 | +# 轻松驾驭Hive数仓 |
| 2 | + |
| 3 | +## 1 前言 |
| 4 | + |
| 5 | +- 先通过SparkSession read API从分布式文件系统创建DataFrame |
| 6 | + |
| 7 | +- 然后,创建临时表并使用SQL或直接使用DataFrame API,进行数据转换、过滤、聚合等操作 |
| 8 | +- 最后,再用SparkSession的write API把计算结果写回分布式文件系统 |
| 9 | + |
| 10 | +直接与文件系统交互,仅是Spark SQL数据应用常见case之一。Spark SQL另一典型场景是与Hive集成、构建分布式数仓。 |
| 11 | + |
| 12 | +数仓,带有主题、聚合层次较高的数据集,承载形式是一系列数据表。数据分析应用很普遍。Hive与Spark联合: |
| 13 | + |
| 14 | +- Hive擅长元数据管理 |
| 15 | +- Spark长高效分布式计算 |
| 16 | + |
| 17 | +Spark与Hive集成方式: |
| 18 | + |
| 19 | +- Spark仅将Hive当成元信息管理工具:Spark with Hive |
| 20 | +- Hive用Spark作底层计算引擎:Hive on Spark |
| 21 | + |
| 22 | +## 2 Hive架构与基本原理 |
| 23 | + |
| 24 | +Hadoop社区构建数仓的核心组件,提供丰富的用户接口,接收用户提交的SQL查询语句。这些查询语句经过Hive解析与优化后,转化为分布式任务,并交付Hadoop MapReduce执行。 |
| 25 | + |
| 26 | +核心: |
| 27 | + |
| 28 | +- User Interface(1) |
| 29 | + |
| 30 | +- Driver(3) |
| 31 | + |
| 32 | +不论元数据库(4)、存储系统(5),还是计算引擎(6),Hive都外包、可插拔式交给第三方独立组件,即专事专人做: |
| 33 | +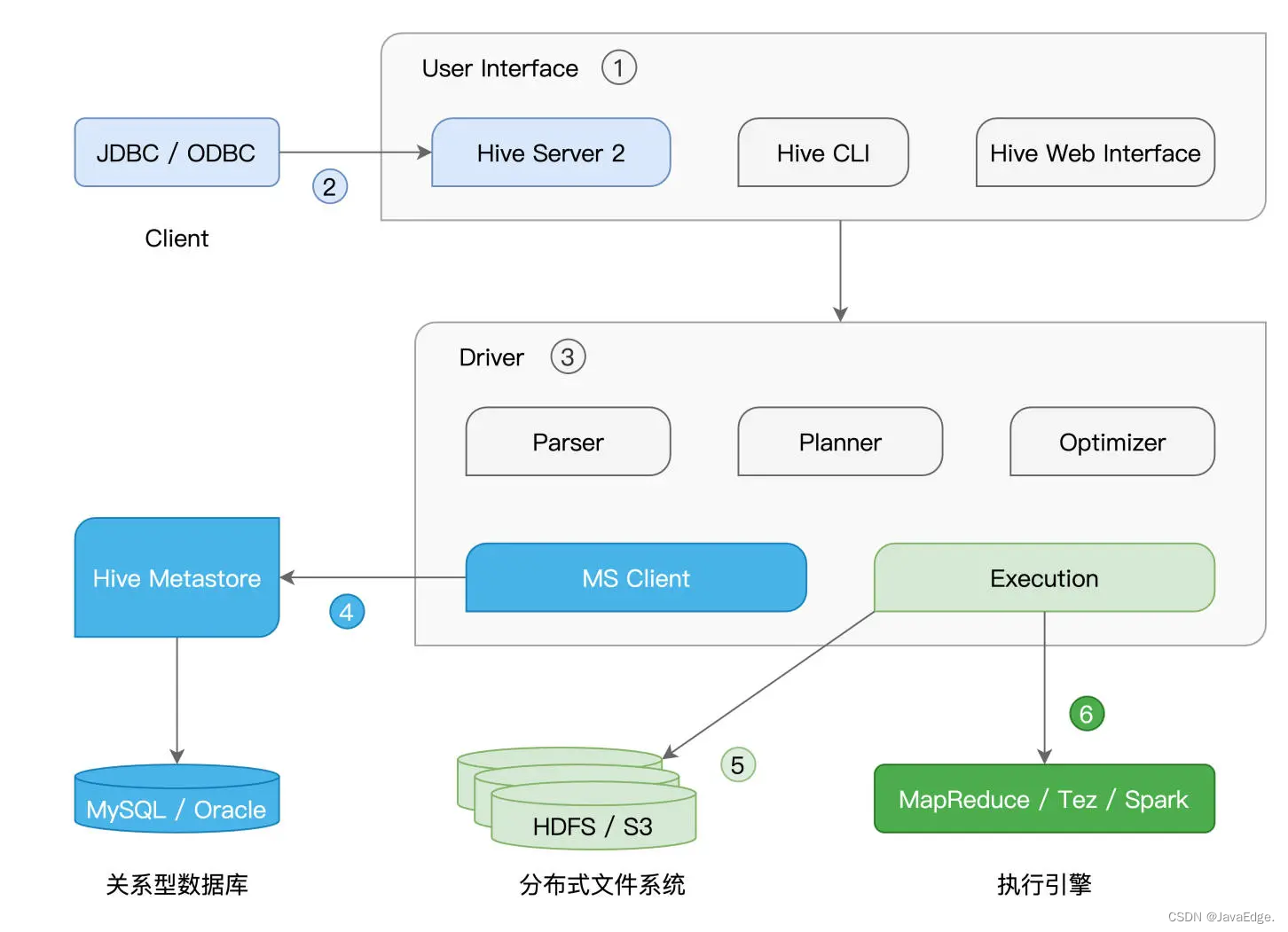 |
| 34 | + |
| 35 | +User Interface为开发者提供SQL接入服务,具体接入途径: |
| 36 | + |
| 37 | +- Hive Server 2(2) |
| 38 | + |
| 39 | + Hive Server 2通过提供JDBC/ODBC客户端连接,允许开发者从远程提交SQL查询请求。该方案更灵活,应用更广泛 |
| 40 | + |
| 41 | +- CLI |
| 42 | + |
| 43 | +- Web Interface(Web界面入口) |
| 44 | + CLI与Web Interface直接在本地接收SQL查询语句 |
| 45 | + |
| 46 | +### Hive Metastore(Hive元数据存储) |
| 47 | + |
| 48 | +普通的RDBMS,可为MySQL、Derby、Oracle、DB2。 |
| 49 | + |
| 50 | +#### 作用 |
| 51 | + |
| 52 | +- 辅助SQL语法解析、执行计划的生成与优化 |
| 53 | +- 帮助底层计算引擎高效地定位并访问分布式文件系统中的数据源 |
| 54 | + |
| 55 | +分布式文件系统可HDFS、Amazon S3。执行方面,Hive支持3类计算引擎: |
| 56 | + |
| 57 | +- Hadoop MapReduce |
| 58 | +- Tez |
| 59 | +- Spark |
| 60 | + |
| 61 | +## 3 Hive工作流程 |
| 62 | + |
| 63 | +- 接收到SQL查询后,Hive的Driver先用Parser组件,将查询语句转化为AST(Abstract Syntax Tree,查询语法树) |
| 64 | +- 接着,Planner组件根据AST生成执行计划 |
| 65 | +- Optimizer进一步优化执行计划 |
| 66 | +- 要完成这一系列的动作,Hive须拿到相关数据表的元信息,如表名、列名、字段类型、数据文件存储路径、文件格式等。这些都存储在“Hive Metastore”(4)数据库 |
| 67 | + |
| 68 | +## 4 Spark with Hive |
| 69 | + |
| 70 | +Hive Metastore利用RDBMS存储数据表的元信息,如表名、表类型、表数据的Schema、表(分区)数据的存储路径、及存储格式。Metastore像“户口簿”,记录分布式文件系统中每一份数据集的“底细”。 |
| 71 | + |
| 72 | +Spark SQL通过访问Hive Metastore,即可扩充数据访问来源,即Spark with Hive核心思想: |
| 73 | + |
| 74 | +- Spark是主体 |
| 75 | +- Hive Metastore只是Spark扩充数据源的辅助 |
| 76 | + |
| 77 | +### 集成方式 |
| 78 | + |
| 79 | + |
| 80 | +1. 创建SparkSession,访问本地或远程的Hive Metastore |
| 81 | +2. 通过Spark内置的spark-sql CLI,访问本地Hive Metastore |
| 82 | +3. 通过Beeline客户端,访问Spark Thrift Server |
| 83 | + |
| 84 | +### SparkSession + Hive Metastore |
| 85 | + |
| 86 | +启动Hive Metastore。 |
| 87 | + |
| 88 | +```scala |
| 89 | +hive --service metastore |
| 90 | +``` |
| 91 | + |
| 92 | +Hive Metastore启动后,要让Spark知道Metastore的访问地址,即告诉他数据源的“户口簿”藏在哪: |
| 93 | + |
| 94 | +- 创建SparkSession时,通过config函数指定hive.metastore.uris参数 |
| 95 | +- 让Spark读取Hive配置文件hive-site.xml,该文件记录Hive相关配置项,包括hive.metastore.uris。把hive-site.xml拷贝到Spark安装目录的conf子目录,Spark即可自行读取内容 |
| 96 | + |
| 97 | +第一种用法案例 |
| 98 | + |
| 99 | +假设Hive有张名为“salaries”的薪资表,每条数据都包含id和salary两个字段,表数据存储在HDFS,那么,在spark-shell中敲入下面的代码,我们即可轻松访问Hive中的数据表。 |
| 100 | + |
| 101 | +```scala |
| 102 | +import org.apache.spark.sql.SparkSession |
| 103 | +import org.apache.spark.sql.DataFrame |
| 104 | + |
| 105 | +val hiveHost: String = _ |
| 106 | +// 创建SparkSession实例 |
| 107 | +val spark = SparkSession.builder() |
| 108 | + .config("hive.metastore.uris", s"thrift://hiveHost:9083") |
| 109 | + .enableHiveSupport() |
| 110 | + .getOrCreate() |
| 111 | + |
| 112 | +// 读取Hive表,创建DataFrame |
| 113 | +val df: DataFrame = spark.sql(“select * from salaries”) |
| 114 | + |
| 115 | +df.show |
| 116 | + |
| 117 | +/** 结果打印 |
| 118 | ++---+------+ |
| 119 | +| id|salary| |
| 120 | ++---+------+ |
| 121 | +| 1| 26000| |
| 122 | +| 2| 30000| |
| 123 | +| 4| 25000| |
| 124 | +| 3| 20000| |
| 125 | ++---+------+ |
| 126 | +*/ |
| 127 | +``` |
| 128 | + |
| 129 | +利用createTempView函数从数据文件创建临时表的方法,临时表创建后,就能使用SparkSession的sql API来提交SQL查询语句。连接到Hive Metastore之后,咱们就可以绕过第一步,直接使用sql API去访问Hive中现有的表,方便! |
| 130 | + |
| 131 | +createTempView创建的临时表,其生命周期仅限于Spark作业内部,一旦作业执行完毕,临时表就不复存在,无法被其他应用复用。而Hive表的元信息已持久化到Hive Metastore,不同的作业、应用、甚至是计算引擎,如Spark、Presto、Impala等,都可以通过Hive Metastore访问Hive表。 |
| 132 | + |
| 133 | +SparkSession + Hive Metastore这种集成,Spark对Hive的访问,仅涉及Metastore,对Hive架构其他组件,Spark并未触及。即Spark仅“白嫖”Hive的Metastore,拿到数据集的元信息后,Spark SQL自行加载数据、处理: |
| 134 | + |
| 135 | + |
| 136 | + |
| 137 | + |
| 138 | + |
| 139 | +在第一种集成方式下,通过sql API,可直接提交复杂SQL,也可以在创建DataFrame之后,再使用各种算子实现业务逻辑。 |
| 140 | + |
| 141 | +### spark-sql CLI + Hive Metastore |
| 142 | + |
| 143 | +“既然是搭建数仓,能不能像用普通数据库,直接输入SQL查询,绕过SparkSession的sql API?”肯定的,Spark with Hive的第二种集成方式:spark-sql CLI + Hive Metastore。 |
| 144 | + |
| 145 | +与spark-shell、spark-submit类似,spark-sql也是Spark内置的系统命令。将配置好hive.metastore.uris参数的hive-site.xml文件放到Spark安装目录的conf下,我们即可在spark-sql中直接使用SQL语句来查询或是处理Hive表。 |
| 146 | + |
| 147 | +显然,在这种集成模式下,Spark和Hive的关系,与刚刚讲的SparkSession + Hive Metastore一样,本质上都是Spark通过Hive Metastore来扩充数据源。 |
| 148 | + |
| 149 | +不过,相比前者,spark-sql CLI的集成方式多了一层限制,那就是在部署上,spark-sql CLI与Hive Metastore必须安装在同一个计算节点。换句话说,spark-sql CLI只能在本地访问Hive Metastore,而没有办法通过远程的方式来做到这一点。 |
| 150 | + |
| 151 | +在绝大多数的工业级生产系统中,不同的大数据组件往往是单独部署的,Hive与Spark也不例外。由于Hive Metastore可用于服务不同的计算引擎,如前面提到的Presto、Impala,因此为了减轻节点的工作负载,Hive Metastore往往会部署到一台相对独立的计算节点。 |
| 152 | + |
| 153 | +在这样的背景下,不得不说,spark-sql CLI本地访问的限制,极大地削弱了它的适用场景,这也是spark-sql CLI + Hive Metastore这种集成方式几乎无人问津的根本原因。不过,这并不妨碍我们学习并了解它,这有助于我们对Spark与Hive之间的关系加深理解。 |
| 154 | + |
| 155 | +### Beeline + Spark Thrift Server |
| 156 | + |
| 157 | +“既然spark-sql CLI有限制,有没有其他集成方式,既能够部署到生产系统,又能让开发者写SQL查询?” 有,Spark with Hive集成的第三种途径,就是使用Beeline客户端,去连接Spark Thrift Server,从而完成Hive表的访问与处理。 |
| 158 | + |
| 159 | +Beeline原是Hive客户端,通过JDBC接入Hive Server 2。Hive Server 2可同时服务多个客户端,提供多租户的Hive查询服务。由于Hive Server 2实现采用Thrift RPC协议框架,因此,很多时候又把Hive Server 2称为“Hive Thrift Server 2”。 |
| 160 | + |
| 161 | +通过Hive Server 2接入的查询请求,经由Hive Driver的解析、规划与优化,交给Hive搭载的计算引擎付诸执行。相应地,查询结果再由Hiver Server 2返还给Beeline客户端,如下图右侧虚线框。 |
| 162 | + |
| 163 | + |
| 164 | + |
| 165 | +Spark Thrift Server脱胎于Hive Server 2,在接收查询、多租户服务、权限管理等方面,这两个服务端的实现逻辑几乎一模一样。它们最大的不同,在于SQL查询接入之后的解析、规划、优化与执行。 |
| 166 | + |
| 167 | +我们刚刚说过,Hive Server 2的“后台”是Hive的那套基础架构。而SQL查询在接入到Spark Thrift Server之后,它首先会交由Spark SQL优化引擎进行一系列的优化。在第14讲我们提过,借助于Catalyst与Tungsten这对“左膀右臂”,Spark SQL对SQL查询语句先后进行语法解析、语法树构建、逻辑优化、物理优化、数据结构优化、以及执行代码优化,等等。然后,Spark SQL将优化过后的执行计划,交付给Spark Core执行引擎付诸运行。 |
| 168 | + |
| 169 | + |
| 170 | + |
| 171 | +SQL查询在接入Spark Thrift Server之后的执行路径,与DataFrame在Spark中的执行路径是完全一致。 |
| 172 | + |
| 173 | +理清Spark Thrift Server与Hive Server 2之间的区别与联系后。 |
| 174 | + |
| 175 | +来看Spark Thrift Server的启动与Beeline的具体用法。 |
| 176 | + |
| 177 | +## 5 启动Spark Thrift Server |
| 178 | + |
| 179 | +只需调用Spark提供的start-thriftserver.sh |
| 180 | + |
| 181 | +```scala |
| 182 | +// SPARK_HOME环境变量,指向Spark安装目录 |
| 183 | +cd $SPARK_HOME/sbin |
| 184 | + |
| 185 | +// 启动Spark Thrift Server |
| 186 | +./start-thriftserver.sh |
| 187 | +``` |
| 188 | + |
| 189 | +脚本执行成功之后,Spark Thrift Server默认在10000端口监听JDBC/ODBC的连接请求。有意思的是,关于监听端口的设置,Spark复用了Hive的hive.server2.thrift.port参数。与其他的Hive参数一样,hive.server2.thrift.port同样要在hive-site.xml配置文件中设置。 |
| 190 | + |
| 191 | +一旦Spark Thrift Server启动成功,我们就可以在任意节点上通过Beeline客户端来访问该服务。在客户端与服务端之间成功建立连接(Connections)之后,咱们就能在Beeline客户端使用SQL语句处理Hive表了。需要注意的是,在这种集成模式下,SQL语句背后的优化与计算引擎是Spark。 |
| 192 | + |
| 193 | +```shell |
| 194 | +/** |
| 195 | +用Beeline客户端连接Spark Thrift Server, |
| 196 | +其中,hostname是Spark Thrift Server服务所在节点 |
| 197 | +*/ |
| 198 | +beeline -u “jdbc:hive2://hostname:10000” |
| 199 | +``` |
| 200 | + |
| 201 | +好啦,到此为止,Spark with Hive这类集成方式我们就讲完了。 |
| 202 | + |
| 203 | +为了巩固刚刚学过的内容,咱们趁热打铁,一起来做个简单的小结。**不论是SparkSession + Hive Metastore、spark-sql CLI + Hive Metastore,还是Beeline + Spark Thrift Server,Spark扮演的角色都是执行引擎,而Hive的作用主要在于通过Metastore提供底层数据集的元数据。不难发现,在这类集成方式中,Spark唱“主角”,而Hive唱“配角”**。 |
| 204 | + |
| 205 | +## 6 Hive on Spark |
| 206 | + |
| 207 | +说到这里,你可能会好奇:“对于Hive社区与Spark社区来说,大家都是平等的,那么有没有Hive唱主角,而Spark唱配角的时候呢?”还真有,这就是Spark与Hive集成的另一种形式:Hive on Spark。 |
| 208 | + |
| 209 | +### 基本原理 |
| 210 | + |
| 211 | +在这一讲的开头,我们简单介绍了Hive的基础架构。Hive的松耦合设计,使得它的Metastore、底层文件系统、以及执行引擎都是可插拔、可替换的。 |
| 212 | + |
| 213 | +在执行引擎方面,Hive默认搭载的是Hadoop MapReduce,但它同时也支持Tez和Spark。所谓的“Hive on Spark”,实际上指的就是Hive采用Spark作为其后端的分布式执行引擎,如下 |
| 214 | + |
| 215 | +从用户的视角来看,使用Hive on MapReduce或是Hive on Tez与使用Hive on Spark没有任何区别,执行引擎的切换对用户来说是完全透明的。不论Hive选择哪一种执行引擎,引擎仅仅负责任务的分布式计算,SQL语句的解析、规划与优化,通通由Hive的Driver来完成。 |
| 216 | + |
| 217 | +为了搭载不同的执行引擎,Hive还需要做一些简单的适配,从而把优化过的执行计划“翻译”成底层计算引擎的语义。 |
| 218 | + |
| 219 | +举例来说,在Hive on Spark的集成方式中,Hive在将SQL语句转换为执行计划之后,还需要把执行计划“翻译”成RDD语义下的DAG,然后再把DAG交付给Spark Core付诸执行。从第14讲到现在,我们一直在强调,Spark SQL除了扮演数据分析子框架的角色之外,还是Spark新一代的优化引擎。 |
| 220 | + |
| 221 | +**在Hive on Spark这种集成模式下,Hive与Spark衔接的部分是Spark Core,而不是Spark SQL**。这也是为什么,相比Hive on Spark,Spark with Hive的集成在执行性能更胜。毕竟,Spark SQL + Spark Core这种原装组合,相比Hive Driver + Spark Core这种适配组合,契合度更高。 |
| 222 | + |
| 223 | +### 集成实现 |
| 224 | + |
| 225 | +分析完原理之后,接下来,我们再来说说,Hive on Spark的集成到底该怎么实现。 |
| 226 | + |
| 227 | +首先,既然我们想让Hive搭载Spark,那么我们事先得准备好一套完备的Spark部署。对于Spark的部署模式,Hive不做任何限定,Spark on Standalone、Spark on Yarn或是Spark on Kubernetes都是可以的。 |
| 228 | + |
| 229 | +Spark集群准备好之后,我们就可以通过修改hive-site.xml中相关的配置项,来轻松地完成Hive on Spark的集成,如下表所示。 |
| 230 | + |
| 231 | + |
| 232 | + |
| 233 | +其中,hive.execution.engine用于指定Hive后端执行引擎,可选值有“mapreduce”、“tez”和“spark”,显然,将该参数设置为“spark”,即表示采用Hive on Spark的集成方式。 |
| 234 | + |
| 235 | +确定了执行引擎之后,接下来我们自然要告诉Hive:“Spark集群部署在哪里”,spark.master正是为了实现这个目的。另外,为了方便Hive调用Spark的相关脚本与Jar包,我们还需要通过spark.home参数来指定Spark的安装目录。 |
| 236 | + |
| 237 | +配置好这3个参数之后,我们就可以用Hive SQL向Hive提交查询请求,而Hive则是先通过访问Metastore在Driver端完成执行计划的制定与优化,然后再将其“翻译”为RDD语义下的DAG,最后把DAG交给后端的Spark去执行分布式计算。 |
| 238 | + |
| 239 | +当你在终端看到“Hive on Spark”的字样时,就证明Hive后台的执行引擎确实是Spark,如下图所示。 |
| 240 | + |
| 241 | +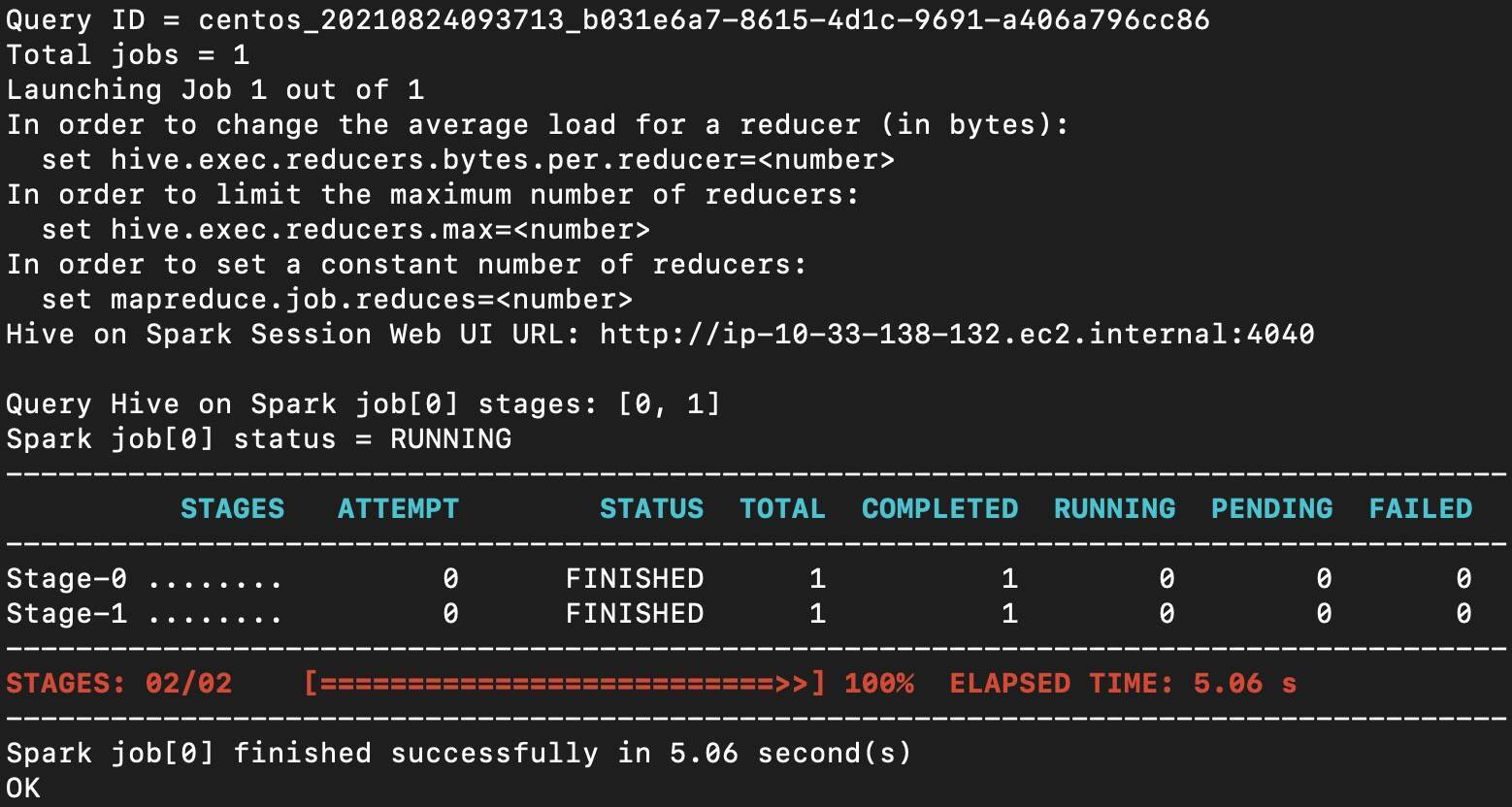 |
| 242 | + |
| 243 | +当然,除了上述3个配置项以外,Hive还提供了更多的参数,用于微调它与Spark之间的交互。对于这些参数,你可以通过访问[Hive on Spark配置项列表](https://cwiki.apache.org/confluence/pages/viewpage.action?pageId=82903061#ConfigurationProperties-Spark)来查看。不仅如此,在第12讲,我们详细介绍了Spark自身的基础配置项,这些配置项都可以配置到hive-site.xml中,方便你更细粒度地控制Hive与Spark之间的集成。 |
| 244 | + |
| 245 | +## 7 总结 |
| 246 | + |
| 247 | +了解Spark与Hive常见的两类集成方式,Spark with Hive和Hive on Spark。前者由Spark社区主导,以Spark为主、Hive为辅;后者则由Hive社区主导,以Hive为主、Spark为辅。两类集成方式各有千秋,适用场景各有不同。 |
| 248 | + |
| 249 | +在Spark with Hive这类集成方式中,Spark主要是利用Hive Metastore来扩充数据源,从而降低分布式文件的管理与维护成本,如路径管理、分区管理、Schema维护,等等。 |
| 250 | + |
| 251 | +对于Spark with Hive,我们至少有3种途径来实现Spark与Hive的集成,分别是SparkSession + Hive Metastore,spark-sql CLI + Hive Metastore和Beeline + Spark Thrift Server。 |
| 252 | + |
| 253 | + |
| 254 | + |
| 255 | +与Spark with Hive相对,另一类集成方式是Hive on Spark。这种集成方式,本质上是Hive社区为Hive用户提供了一种新的选项,这个选项就是,在执行引擎方面,除了原有的MapReduce与Tez,开发者还可以选择执行性能更佳的Spark。 |
| 256 | + |
| 257 | +Spark大行其道当下,习惯使用Hive的团队与开发者,更愿意尝试和采用Spark作为后端的执行引擎。 |
0 commit comments