|
| 1 | +# Spark架构 |
| 2 | + |
| 3 | +相比MapReduce僵化的Map与Reduce分阶段计算,Spark计算框架更有弹性和灵活性,运行性能更佳。 |
| 4 | + |
| 5 | +## 1 Spark的计算阶段 |
| 6 | + |
| 7 | +- MapReduce一个应用一次只运行一个map和一个reduce |
| 8 | +- Spark可根据应用复杂度,分割成更多的计算阶段(stage),组成一个DAG,Spark任务调度器可根据DAG依赖关系执行计算阶段 |
| 9 | + |
| 10 | +逻辑回归机器学习性能Spark比MapReduce快100多倍。因某些机器学习算法可能需大量迭代计算,产生数万个计算阶段,这些计算阶段在一个应用中处理完成,而不像MapReduce需要启动数万个应用,因此运行效率极高。 |
| 11 | + |
| 12 | +DAG,不同阶段的依赖关系有向,计算过程只能沿依赖关系方向执行,被依赖的阶段执行完成前,依赖的阶段不能开始执行。该依赖关系不能有环形依赖,否则就死循环。 |
| 13 | + |
| 14 | +典型的Spark运行DAG的不同阶段: |
| 15 | + |
| 16 | + |
| 17 | + |
| 18 | +整个应用被切分成3个阶段,阶段3依赖阶段1、2,阶段1、2互不依赖。Spark执行调度时,先执行阶段1、2,完成后,再执行阶段3。对应Spark伪代码: |
| 19 | + |
| 20 | +```scala |
| 21 | +rddB = rddA.groupBy(key) |
| 22 | +rddD = rddC.map(func) |
| 23 | +rddF = rddD.union(rddE) |
| 24 | +rddG = rddB.join(rddF) |
| 25 | +``` |
| 26 | + |
| 27 | +所以Spark作业调度执行核心是DAG,整个应用被切分成数个阶段,每个阶段的依赖关系也很清楚。根据每个阶段要处理的数据量生成任务集合(TaskSet),每个任务都分配一个任务进程去处理,Spark就实现大数据分布式计算。 |
| 28 | + |
| 29 | +负责Spark应用DAG生成和管理的组件是DAGScheduler: |
| 30 | + |
| 31 | +- DAGScheduler根据程序代码生成DAG |
| 32 | +- 然后将程序分发到分布式计算集群 |
| 33 | +- 按计算阶段的先后关系调度执行 |
| 34 | + |
| 35 | +### Spark划分计算阶段的依据是啥? |
| 36 | + |
| 37 | +显然并非RDD上的每个转换函数都会生成一个计算阶段,如上4个转换函数,但只有3个阶段。 |
| 38 | + |
| 39 | +观察上面DAG图,关于计算阶段的划分从图上就能看出,当RDD之间的转换连接线呈现多对多交叉连接时,就会产生新阶段。一个RDD代表一个数据集,图中每个RDD里面都包含多个小块,每个小块代表RDD的一个分片。 |
| 40 | + |
| 41 | +一个数据集中的多个数据分片需要进行分区传输,写入到另一个数据集的不同分片中,这种数据分区交叉传输的操作,我们在MapReduce的运行过程中也看到过。 |
| 42 | + |
| 43 | + |
| 44 | + |
| 45 | +是的,这就是shuffle过程,Spark也需要通过shuffle将数据进行重新组合,相同Key的数据放在一起,进行聚合、关联等操作,因而每次shuffle都产生新的计算阶段。这也是为什么计算阶段会有依赖关系,它需要的数据来源于前面一个或多个计算阶段产生的数据,必须等待前面的阶段执行完毕才能进行shuffle,并得到数据。 |
| 46 | + |
| 47 | +**计算阶段划分依据是shuffle,而非转换函数的类型**,有的函数有时有shuffle,有时无。如上图例子中RDD B和RDD F进行join,得到RDD G,这里的RDD F需要进行shuffle,RDD B不需要。 |
| 48 | + |
| 49 | +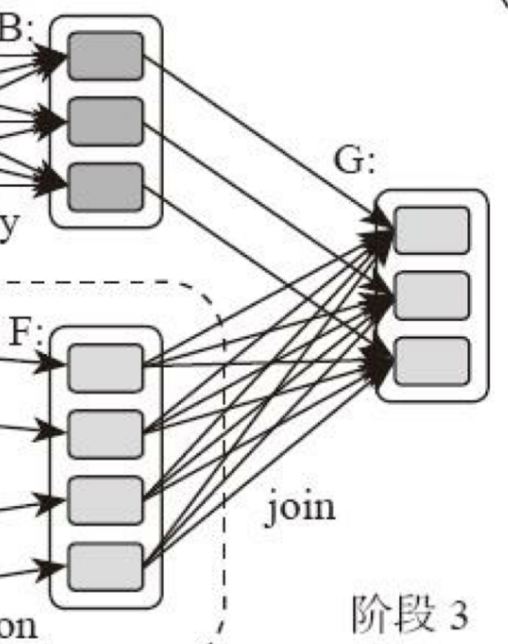 |
| 50 | + |
| 51 | +因为RDD B在前面一个阶段,阶段1的shuffle过程中,已进行了数据分区。分区数目和分区K不变,无需再shuffle: |
| 52 | + |
| 53 | +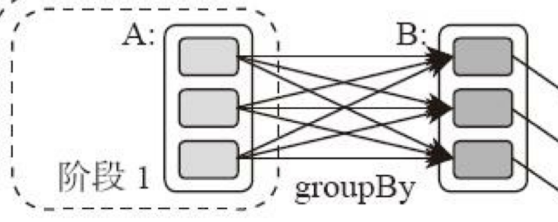 |
| 54 | + |
| 55 | +- 这种无需进行shuffle的依赖,在Spark里称作窄依赖 |
| 56 | +- 需要进行shuffle的依赖,被称作宽依赖 |
| 57 | + |
| 58 | +类似MapReduce,shuffle对Spark也很重要,只有通过shuffle,相关数据才能互相计算。 |
| 59 | + |
| 60 | +既然都要shuffle,为何Spark就更高效? |
| 61 | + |
| 62 | +本质上,Spark算是一种MapReduce计算模型的不同实现。Hadoop MapReduce简单粗暴根据shuffle将大数据计算分成Map、Reduce两阶段就完事。但Spark更细,将前一个的Reduce和后一个的Map连接,当作一个阶段持续计算,形成一个更优雅、高效地计算模型,其本质依然是Map、Reduce。但这种多个计算阶段依赖执行的方案可有效减少对HDFS的访问,减少作业的调度执行次数,因此执行速度更快。 |
| 63 | + |
| 64 | +不同于Hadoop MapReduce主要使用磁盘存储shuffle过程中的数据,Spark优先使用内存进行数据存储,包括RDD数据。除非内存不够用,否则尽可能使用内存, 这也是Spark性能比Hadoop高的原因。 |
| 65 | + |
| 66 | +## 2 Spark作业管理 |
| 67 | + |
| 68 | +Spark里面的RDD函数有两种: |
| 69 | + |
| 70 | +- 转换函数,调用以后得到的还是一个RDD,RDD的计算逻辑主要通过转换函数完成 |
| 71 | +- action函数,调用以后不再返回RDD。比如**count**()函数,返回RDD中数据的元素个数 |
| 72 | +- saveAsTextFile(path),将RDD数据存储到path路径 |
| 73 | + |
| 74 | +Spark的DAGScheduler在遇到shuffle的时候,会生成一个计算阶段,在遇到action函数的时候,会生成一个作业(job) |
| 75 | + |
| 76 | +RDD里面的每个数据分片,Spark都会创建一个计算任务去处理,所以一个计算阶段含多个计算任务(task)。 |
| 77 | + |
| 78 | +作业、计算阶段、任务的依赖和时间先后关系: |
| 79 | + |
| 80 | +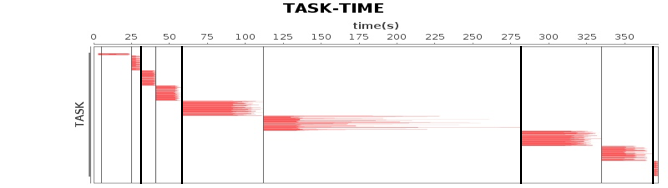 |
| 81 | + |
| 82 | +横轴时间,纵轴任务。两条粗黑线之间是一个作业,两条细线之间是一个计算阶段。一个作业至少包含一个计算阶段。水平方向红色的线是任务,每个阶段由很多个任务组成,这些任务组成一个任务集合。 |
| 83 | + |
| 84 | +DAGScheduler根据代码生成DAG图后,Spark任务调度就以任务为单位进行分配,将任务分配到分布式集群的不同机器上执行。 |
| 85 | + |
| 86 | +## 3 Spark执行流程 |
| 87 | + |
| 88 | +Spark支持Standalone、Yarn、Mesos、K8s等多种部署方案,原理类似,仅是不同组件的角色命名不同。 |
| 89 | + |
| 90 | +### Spark cluster components |
| 91 | + |
| 92 | + |
| 93 | + |
| 94 | +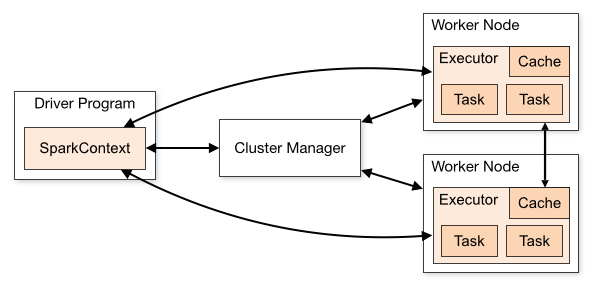 |
| 95 | + |
| 96 | +首先,Spark应用程序启动在自己的JVM进程里(Driver进程),启动后调用SparkContext初始化执行配置和输入数据。SparkContext启动DAGScheduler构造执行的DAG图,切分成最小的执行单位-计算任务。 |
| 97 | + |
| 98 | +然后,Driver向Cluster Manager请求计算资源,用于DAG的分布式计算。Cluster Manager收到请求后,将Driver的主机地址等信息通知给集群的所有计算节点Worker。 |
| 99 | + |
| 100 | +Worker收到信息后,根据Driver的主机地址,跟Driver通信并注册,然后根据自己的空闲资源向Driver通报自己可以领用的任务数。Driver根据DAG图开始向注册的Worker分配任务。 |
| 101 | + |
| 102 | +Worker收到任务后,启动Executor进程执行任务。Executor先检查自己是否有Driver的执行代码,若无,从Driver下载执行代码,通过Java反射加载后开始执行。 |
| 103 | + |
| 104 | +## 4 Spark V.S Hadoop |
| 105 | + |
| 106 | +个体对比: |
| 107 | + |
| 108 | +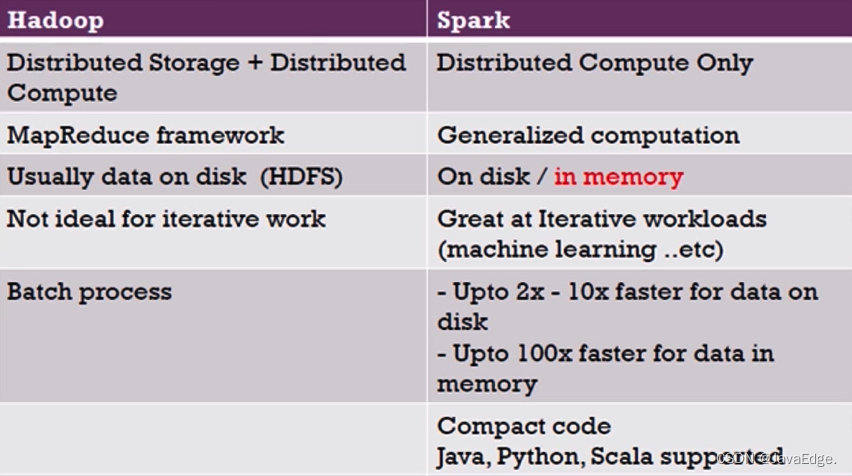 |
| 109 | + |
| 110 | +生态圈对比: |
| 111 | + |
| 112 | +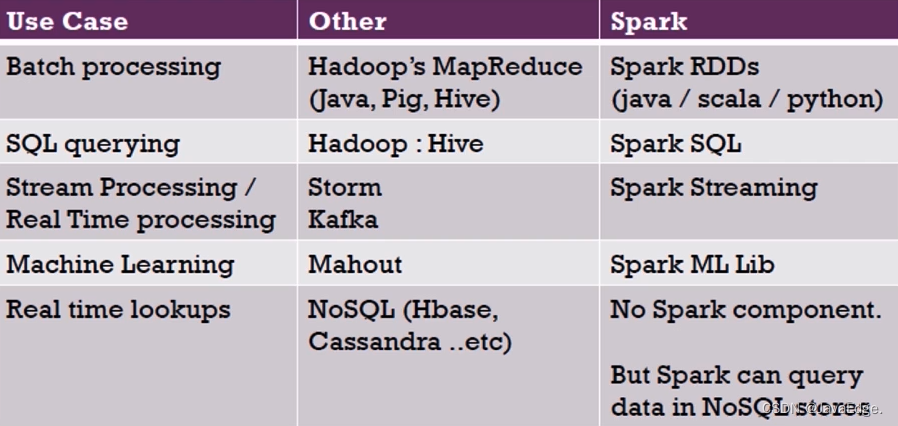 |
| 113 | + |
| 114 | +MapReduce V.S Spark |
| 115 | + |
| 116 | +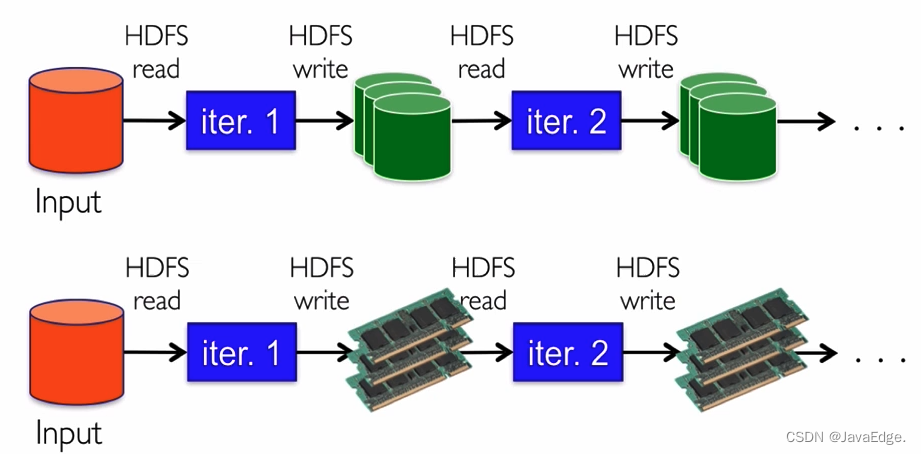 |
| 117 | + |
| 118 | +## 优势 |
| 119 | + |
| 120 | + |
| 121 | + |
| 122 | +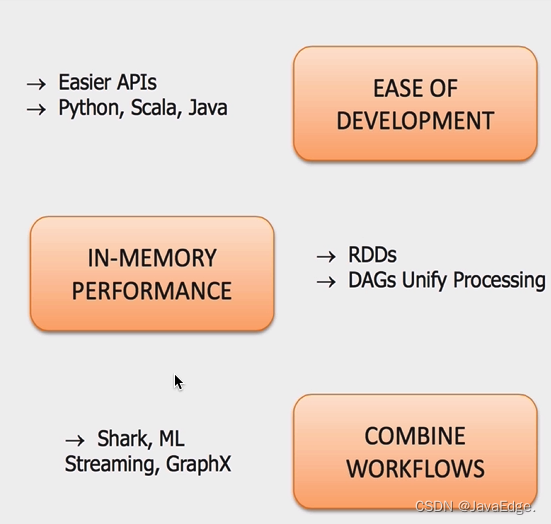 |
| 123 | + |
| 124 | +## Spark 和 Hadoop 协作 |
| 125 | + |
| 126 | + |
| 127 | + |
| 128 | + |
| 129 | + |
| 130 | + |
| 131 | + |
| 132 | +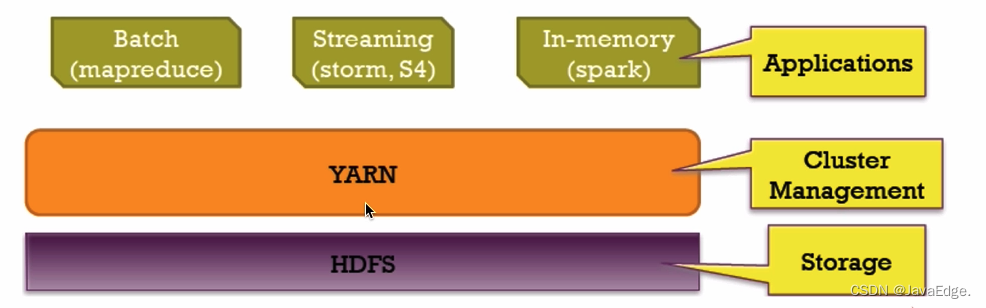 |
| 133 | + |
| 134 | +## 5 总结 |
| 135 | + |
| 136 | +相比Mapreduce,Spark的主要特性: |
| 137 | + |
| 138 | +- RDD编程模型更简单 |
| 139 | +- DAG切分的多阶段计算过程更快 |
| 140 | +- 使用内存存储中间计算结果更高效 |
| 141 | + |
| 142 | +Spark在2012开始流行,那时内存容量提升和成本降低已经比MapReduce出现的十年前强了一个数量级,Spark优先使用内存的条件已成熟。 |
| 143 | + |
| 144 | +*Edit from 2015/12/17: Memory model described in this article is deprecated starting Apache Spark 1.6+, the new memory model is based on UnifiedMemoryManager and described in [this article](https://0x0fff.com/spark-memory-management/)* |
| 145 | + |
| 146 | +Over the recent time I’ve answered a series of questions related to ApacheSpark architecture on StackOverflow. All of them seem to be caused by the absence of a good general description of the Spark architecture in the internet. Even official guide does not have that many details and of cause it lacks good diagrams. Same for the “Learning Spark” book and the materials of official workshops. |
| 147 | + |
| 148 | +In this article I would try to fix this and provide a single-stop shop guide for Spark architecture in general and some most popular questions on its concepts. This article is not for complete beginners – it will not provide you an insight on the Spark main programming abstractions (RDD and DAG), but requires their knowledge as a prerequisite. |
| 149 | + |
| 150 | +This is the first article in a series. The second one regarding shuffle [is available here](https://0x0fff.com/spark-architecture-shuffle/). The third one about new memory management model [is available here](https://0x0fff.com/spark-memory-management/). |
| 151 | + |
| 152 | + |
| 153 | + |
| 154 | +Let’s start with the official picture available on the http://spark.apache.org/docs/1.3.0/cluster-overview.html: |
| 155 | + |
| 156 | +[](https://i0.wp.com/0x0fff.com/wp-content/uploads/2015/03/Spark-Architecture-Official.png) |
| 157 | + |
| 158 | +As you might see, it has many terms introduced at the same time – “executor”, “task”, “cache”, “Worker Node” and so on. When I started to learn the Spark concepts some time ago, it was almost the only picture about Spark architecture available over the internet and now the things didn’t change much. I personally don’t really like this because it does not show some important concepts or shows them not in the best way. |
| 159 | + |
| 160 | +Let’s start from the beginning. Any, any Spark process that would ever work on your cluster or local machine is a JVM process. As for any JVM process, you can configure its heap size with *-Xmx* and *-Xms* flags of the JVM. How does this process use its heap memory and why does it need it at all? Here’s the diagram of Spark memory allocation inside of the JVM heap: |
| 161 | + |
| 162 | + |
| 163 | + |
| 164 | +By default, Spark starts with 512MB JVM heap. To be on a safe side and avoid OOM error Spark allows to utilize only 90% of the heap, which is controlled by the *spark.storage.safetyFraction* parameter of Spark. Ok, as you might have heard of Spark as an in-memory tool, Spark allows you to store some data in memory. If you have read my article here https://0x0fff.com/spark-misconceptions/, you should understand that Spark is not really in-memory tool, it just utilizes the memory for its LRU cache (http://en.wikipedia.org/wiki/Cache_algorithms). So some amount of memory is reserved for the caching of the data you are processing, and this part is usually 60% of the safe heap, which is controlled by the *spark.storage.memoryFraction* parameter. So if you want to know how much data you can cache in Spark, you should take the sum of all the heap sizes for all the executors, multiply it by *safetyFraction* and by *storage.memoryFraction*, and by default it is 0.9 * 0.6 = 0.54 or 54% of the total heap size you allow Spark to use. |
| 165 | + |
| 166 | +Now a bit more about the shuffle memory. It is calculated as “Heap Size” * *spark.shuffle.safetyFraction* * *spark.shuffle.memoryFraction*. Default value for *spark.shuffle.safetyFraction* is 0.8 or 80%, default value for *spark.shuffle.memoryFraction* is 0.2 or 20%. So finally you can use up to 0.8*0.2 = 0.16 or 16% of the JVM heap for the shuffle. But how does Spark uses this memory? You can get more details on this here (https://github.com/apache/spark/blob/branch-1.3/core/src/main/scala/org/apache/spark/shuffle/ShuffleMemoryManager.scala), but in general Spark uses this memory for the exact task it is called after – for Shuffle. When the shuffle is performed, sometimes you as well need to sort the data. When you sort the data, you usually need a buffer to store the sorted data (remember, you cannot modify the data in the LRU cache in place as it is there to be reused later). So it needs some amount of RAM to store the sorted chunks of data. What happens if you don’t have enough memory to sort the data? There is a wide range of algorithms usually referenced as “external sorting” (http://en.wikipedia.org/wiki/External_sorting) that allows you to sort the data chunk-by-chunk and then merge the final result together. |
| 167 | + |
| 168 | +The last part of RAM I haven’t yet cover is “unroll” memory. The amount of RAM that is allowed to be utilized by unroll process is *spark.storage.unrollFraction* * *spark.storage.memoryFraction* * *spark.storage.safetyFraction*, which with the default values equal to 0.2 * 0.6 * 0.9 = 0.108 or 10.8% of the heap. This is the memory that can be used when you are unrolling the block of data into the memory. Why do you need to unroll it after all? Spark allows you to store the data both in serialized and deserialized form. The data in serialized form cannot be used directly, so you have to unroll it before using, so this is the RAM that is used for unrolling. It is shared with the storage RAM, which means that if you need some memory to unroll the data, this might cause dropping some of the partitions stored in the Spark LRU cache. |
| 169 | + |
| 170 | +This is great, because at the moment you know what exactly Spark process is and how it utilizes the memory of its JVM processes. Now let’s switch to the cluster mode – when you start a Spark cluster, how does it really look like? I like YARN so I would cover how it works in YARN, but in general it is the same for any cluster manager you use: |
| 171 | + |
| 172 | +[](https://i0.wp.com/0x0fff.com/wp-content/uploads/2015/03/Spark-Architecture-On-YARN.png) |
| 173 | + |
| 174 | +When you have a YARN cluster, it has a YARN Resource Manager daemon that controls the cluster resources (practically memory) and a series of YARN Node Managers running on the cluster nodes and controlling node resource utilization. From the YARN standpoint, each node represents a pool of RAM that you have a control over. When you request some resources from YARN Resource Manager, it gives you information of which Node Managers you can contact to bring up the execution containers for you. Each execution container is a JVM with requested heap size. JVM locations are chosen by the YARN Resource Manager and you have no control over it – if the node has 64GB of RAM controlled by YARN (*yarn.nodemanager.resource.memory-mb* setting in yarn-site.xml) and you request 10 executors with 4GB each, all of them can be easily started on a single YARN node even if you have a big cluster. |
| 175 | + |
| 176 | +When you start Spark cluster on top of YARN, you specify the amount of executors you need (*–num-executors* flag or *spark.executor.instances* parameter), amount of memory to be used for each of the executors (*–executor-memory* flag or *spark.executor.memory* parameter), amount of cores allowed to use for each executors (*–executor-cores* flag of *spark.executor.cores* parameter), and amount of cores dedicated for each task’s execution (*spark.task.cpus* parameter). Also you specify the amount of memory to be used by the driver application (*–driver-memory* flag or *spark.driver.memory* parameter). |
| 177 | + |
| 178 | +When you execute something on a cluster, the processing of your job is split up into stages, and each stage is split into tasks. Each task is scheduled separately. You can consider each of the JVMs working as executors as a pool of task execution slots, each executor would give you *spark.executor.cores* / *spark.task.cpus* execution slots for your tasks, with a total of *spark.executor.instances* executors. Here’s an example. The cluster with 12 nodes running YARN Node Managers, 64GB of RAM each and 32 CPU cores each (16 physical cores with hyper threading). This way on each node you can start 2 executors with 26GB of RAM each (leave some RAM for system processes, YARN NM and DataNode), each executor with 12 cores to be utilized for tasks (leave some cores for system processes, YARN NM and DataNode). So In total your cluster would handle 12 machines * 2 executors per machine * 12 cores per executor / 1 core for each task = 288 task slots. This means that your Spark cluster would be able to run up to 288 tasks in parallel thus utilizing almost all the resources you have on this cluster. The amount of RAM you can use for caching your data on this cluster is 0.9 *spark.storage.safetyFraction* * 0.6 *spark.storage.memoryFraction* * 12 machines * 2 executors per machine * 26 GB per executor = 336.96 GB. Not that much, but in most cases it is enough. |
| 179 | + |
| 180 | +So far so good, now you know how the Spark uses its JVM’s memory and what are the execution slots you have on your cluster. As you might already noticed, I didn’t stop in details on what the “task” really is. This would be a subject of the next article, but basically it is a single unit of work performed by Spark, and is executed as a ***thread\*** in the executor JVM. This is the secret under the Spark low job startup time – forking additional thread inside of the JVM is much faster that bringing up the whole JVM, which is performed when you start a MapReduce job in Hadoop. |
| 181 | + |
| 182 | +Now let’s focus on another Spark abstraction called “***partition***”. All the data you work with in Spark is split into partitions. What a single partition is and how is it determined? Partition size completely depends on the data source you use. For most of the methods to read the data in Spark you can specify the amount of partitions you want to have in your RDD. When you read a file from HDFS, you use Hadoop’s InputFormat to make it. By default each input split returned by InputFormat is mapped to a single partition in RDD. For most of the files on HDFS single input split is generated for a single block of data stored on HDFS, which equals to approximately 64MB of 128MB of data. Approximately, because the data in HDFS is split on exact block boundaries in bytes, but when it is processed it is split on the record splits. For text file the splitting character is the newline char, for sequence file it is the block end and so on. The only exception of this rule is compressed files – if you have the whole text file compressed, then it cannot be split into records and the whole file would become a single input split and thus a single partition in Spark and you have to manually repartition it. |
| 183 | + |
| 184 | +And what we have now is really simple – to process a single partition of data Spark spawns a single task, which is executed in task slot located close to the data you have (Hadoop block location, Spark cached partition location). |
| 185 | + |
| 186 | +This information is more than enough for a single article. In the next one I would cover how Spark splits the execution process into stages and stages into tasks, how Spark shuffles the data through the cluster and some more useful things. |
| 187 | + |
| 188 | +This is the first article in a series. The second one regarding shuffle [is available here](https://0x0fff.com/spark-architecture-shuffle/). The third one about new memory management model [is available here](https://0x0fff.com/spark-memory-management/). |
| 189 | + |
| 190 | +> 参考 |
| 191 | +> |
| 192 | +> - https://spark.apache.org/docs/3.2.1/cluster-overview.html |
0 commit comments