|
| 1 | +# DolphinScheduler资源中心 |
| 2 | + |
| 3 | +## 1 简介 |
| 4 | + |
| 5 | +资源中心通常用于上传文件、UDF 函数和任务组管理。 |
| 6 | + |
| 7 | +- standalone 环境可选择本地文件目录作为上传文件夹(无需Hadoop部署) |
| 8 | +- 也可选择上传到 Hadoop 或 MinIO 集群。此时需要有 Hadoop(2.6+)或 MinIO 等相关环境 |
| 9 | + |
| 10 | +## 2 配置详情 |
| 11 | + |
| 12 | +- 资源中心可对接分布式文件存储系统,如[Hadoop](https://hadoop.apache.org/docs/r2.7.0/)(2.6+)或[MinIO](https://github.com/minio/minio)集群,也可对接远端的对象存储如[AWS S3](https://aws.amazon.com/s3/)或者[阿里云 OSS](https://www.aliyun.com/product/oss),[华为云 OBS](https://support.huaweicloud.com/obs/index.html)。 |
| 13 | +- 也可直接对接本地文件系统。单机模式无需依赖`Hadoop`或`S3`一类的外部存储系统,可方便对接本地文件系统体验 |
| 14 | +- 集群模式部署,可用[S3FS-FUSE](https://github.com/s3fs-fuse/s3fs-fuse)将`S3`挂载到本地或用[JINDO-FUSE](https://help.aliyun.com/document_detail/187410.html)将`OSS`挂载到本地等,再用资源中心对接本地文件系统方式来操作远端对象存储中的文件 |
| 15 | + |
| 16 | +### 2.1 对接本地文件系统 |
| 17 | + |
| 18 | +#### `common.properties` |
| 19 | + |
| 20 | +资源中心使用本地系统默认开启,但若你需修改默认配置,请确保同时完成下面修改: |
| 21 | + |
| 22 | +- 如以 `集群` 或 `伪集群` 模式部署,需对以下路径的文件配置:`api-server/conf/common.properties` 和 `worker-server/conf/common.properties` |
| 23 | +- `单机` 模式部署,只需配置 `standalone-server/conf/common.properties` |
| 24 | + |
| 25 | +可能涉及修改: |
| 26 | + |
| 27 | +- `resource.storage.upload.base.path` 改为本地存储路径,请确保部署 DolphinScheduler 的用户拥有读写权限,如:`resource.storage.upload.base.path=/tmp/dolphinscheduler`。当路径不存在时会自动创建文件夹 |
| 28 | + |
| 29 | +> **注意** |
| 30 | +> |
| 31 | +> 1. LOCAL模式不支持分布式模式读写,意味着上传的资源只能在一台机器上使用,除非使用共享文件挂载点 |
| 32 | +> 2. 如不想用默认值作为资源中心的基础路径,修改`resource.storage.upload.base.path` |
| 33 | +> 3. 当配置 `resource.storage.type=LOCAL`,其实配置了两个配置项 `resource.storage.type=HDFS` 和 `resource.hdfs.fs.defaultFS=file:///` ,单独配置 `resource.storage.type=LOCAL` 这个值是为了 方便用户,并且能使得本地资源中心默认开启 |
| 34 | +
|
| 35 | +#### 确保在HDFS上有指定的目录并具有读写权限 |
| 36 | + |
| 37 | +1. **登录到HDFS**: 使用具有适当权限的用户账号登录到HDFS集群中的任一节点或者使用Hadoop客户端工具登录。 |
| 38 | + |
| 39 | +2. **检查目录是否存在**: 执行以下命令来检查指定的目录是否已存在于HDFS |
| 40 | + |
| 41 | + ```bash |
| 42 | + hdfs dfs -ls /dolphinscheduler |
| 43 | + ls: `/dolphinscheduler': No such file or directory |
| 44 | + ``` |
| 45 | +
|
| 46 | + 如果目录已存在,将会列出目录下的文件信息。如果不存在,提示找不到该路径。 |
| 47 | +
|
| 48 | +3. **创建目录**: 目录不存在,则用命令在HDFS创建: |
| 49 | +
|
| 50 | + ```bash |
| 51 | + hdfs dfs -mkdir -p /dolphinscheduler |
| 52 | + ``` |
| 53 | +
|
| 54 | + 将递归创建所需的目录结构。 |
| 55 | +
|
| 56 | +4. **设置权限**: 确保创建的目录具有适当权限,以便DolphinScheduler可以读取和写入该目录。设置权限: |
| 57 | +
|
| 58 | + ```bash |
| 59 | + hdfs dfs -chmod -R 777 /dolphinscheduler |
| 60 | + ``` |
| 61 | +
|
| 62 | + 这将给予目录及其所有子目录和文件读取、写入和执行的权限。 |
| 63 | +
|
| 64 | +5. **验证权限设置**: 可以再次运行以下命令来验证目录的权限设置是否正确: |
| 65 | +
|
| 66 | + ```bash |
| 67 | + hdfs dfs -ls /dolphinscheduler |
| 68 | + ``` |
| 69 | +
|
| 70 | + 确保您看到的输出中包含了该目录的详细信息,并且权限设置为读写执行权限。 |
| 71 | +
|
| 72 | +通过以上步骤,可确保在HDFS上有指定的目录并且具有读写权限,以供DolphinScheduler存储和访问资源文件。 |
| 73 | +
|
| 74 | +### 2.2 对接分布式或远端对象存储 |
| 75 | +
|
| 76 | +当需要使用资源中心进行相关文件的创建或者上传操作时,所有的文件和资源都会被存储在分布式文件系统`HDFS`或者远端的对象存储,如`S3`上。需配置: |
| 77 | +
|
| 78 | +#### common.properties |
| 79 | +
|
| 80 | +在 3.0.0-alpha 版本之后,如果需要使用到资源中心的 HDFS 或 S3 上传资源,我们需要对以下路径的进行配置:`api-server/conf/common.properties` 和 `worker-server/conf/common.properties`。可参考如下: |
| 81 | +
|
| 82 | +```properties |
| 83 | +# |
| 84 | +# Licensed to the Apache Software Foundation (ASF) under one or more |
| 85 | +# contributor license agreements. See the NOTICE file distributed with |
| 86 | +# this work for additional information regarding copyright ownership. |
| 87 | +# The ASF licenses this file to You under the Apache License, Version 2.0 |
| 88 | +# (the "License"); you may not use this file except in compliance with |
| 89 | +# the License. You may obtain a copy of the License at |
| 90 | +# |
| 91 | +# http://www.apache.org/licenses/LICENSE-2.0 |
| 92 | +# |
| 93 | +# Unless required by applicable law or agreed to in writing, software |
| 94 | +# distributed under the License is distributed on an "AS IS" BASIS, |
| 95 | +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. |
| 96 | +# See the License for the specific language governing permissions and |
| 97 | +# limitations under the License. |
| 98 | +# |
| 99 | +
|
| 100 | +# user data local directory path, please make sure the directory exists and have read write permissions |
| 101 | +data.basedir.path=/tmp/dolphinscheduler |
| 102 | +
|
| 103 | +# resource storage type: LOCAL, HDFS, S3, OSS, GCS, ABS, OBS |
| 104 | +resource.storage.type=LOCAL |
| 105 | +
|
| 106 | +# resource store on HDFS/S3/OSS path, resource file will store to this hadoop hdfs path, self configuration, |
| 107 | +# please make sure the directory exists on hdfs and have read write permissions. "/dolphinscheduler" is recommended |
| 108 | +resource.storage.upload.base.path=/tmp/dolphinscheduler |
| 109 | +
|
| 110 | +# The AWS access key. if resource.storage.type=S3 or use EMR-Task, This configuration is required |
| 111 | +resource.aws.access.key.id=minioadmin |
| 112 | +# The AWS secret access key. if resource.storage.type=S3 or use EMR-Task, This configuration is required |
| 113 | +resource.aws.secret.access.key=minioadmin |
| 114 | +# The AWS Region to use. if resource.storage.type=S3 or use EMR-Task, This configuration is required |
| 115 | +resource.aws.region=cn-north-1 |
| 116 | +# The name of the bucket. You need to create them by yourself. Otherwise, the system cannot start. All buckets in Amazon S3 share a single namespace; ensure the bucket is given a unique name. |
| 117 | +resource.aws.s3.bucket.name=dolphinscheduler |
| 118 | +# You need to set this parameter when private cloud s3. If S3 uses public cloud, you only need to set resource.aws.region or set to the endpoint of a public cloud such as S3.cn-north-1.amazonaws.com.cn |
| 119 | +resource.aws.s3.endpoint=http://localhost:9000 |
| 120 | +
|
| 121 | +# alibaba cloud access key id, required if you set resource.storage.type=OSS |
| 122 | +resource.alibaba.cloud.access.key.id=<your-access-key-id> |
| 123 | +# alibaba cloud access key secret, required if you set resource.storage.type=OSS |
| 124 | +resource.alibaba.cloud.access.key.secret=<your-access-key-secret> |
| 125 | +# alibaba cloud region, required if you set resource.storage.type=OSS |
| 126 | +resource.alibaba.cloud.region=cn-hangzhou |
| 127 | +# oss bucket name, required if you set resource.storage.type=OSS |
| 128 | +resource.alibaba.cloud.oss.bucket.name=dolphinscheduler |
| 129 | +# oss bucket endpoint, required if you set resource.storage.type=OSS |
| 130 | +resource.alibaba.cloud.oss.endpoint=https://oss-cn-hangzhou.aliyuncs.com |
| 131 | +
|
| 132 | +# alibaba cloud access key id, required if you set resource.storage.type=OBS |
| 133 | +resource.huawei.cloud.access.key.id=<your-access-key-id> |
| 134 | +# alibaba cloud access key secret, required if you set resource.storage.type=OBS |
| 135 | +resource.huawei.cloud.access.key.secret=<your-access-key-secret> |
| 136 | +# oss bucket name, required if you set resource.storage.type=OBS |
| 137 | +resource.huawei.cloud.obs.bucket.name=dolphinscheduler |
| 138 | +# oss bucket endpoint, required if you set resource.storage.type=OBS |
| 139 | +resource.huawei.cloud.obs.endpoint=obs.cn-southwest-2.huaweicloud.com |
| 140 | +
|
| 141 | +# if resource.storage.type=HDFS, the user must have the permission to create directories under the HDFS root path |
| 142 | +resource.hdfs.root.user=root |
| 143 | +# if resource.storage.type=S3, the value like: s3a://dolphinscheduler; |
| 144 | +# if resource.storage.type=HDFS and namenode HA is enabled, you need to copy core-site.xml and hdfs-site.xml to conf dir |
| 145 | +resource.hdfs.fs.defaultFS=hdfs://localhost:8020 |
| 146 | +
|
| 147 | +# whether to startup kerberos |
| 148 | +hadoop.security.authentication.startup.state=false |
| 149 | +
|
| 150 | +# java.security.krb5.conf path |
| 151 | +java.security.krb5.conf.path=/opt/krb5.conf |
| 152 | +
|
| 153 | +# login user from keytab username |
| 154 | +login.user.keytab.username=hdfs-mycluster@ESZ.COM |
| 155 | +
|
| 156 | +# login user from keytab path |
| 157 | +login.user.keytab.path=/opt/hdfs.headless.keytab |
| 158 | +
|
| 159 | +# kerberos expire time, the unit is hour |
| 160 | +kerberos.expire.time=2 |
| 161 | +# resource view suffixs |
| 162 | +#resource.view.suffixs=txt,log,sh,bat,conf,cfg,py,java,sql,xml,hql,properties,json,yml,yaml,ini,js |
| 163 | +
|
| 164 | +# resourcemanager port, the default value is 8088 if not specified |
| 165 | +resource.manager.httpaddress.port=8088 |
| 166 | +# if resourcemanager HA is enabled, please set the HA IPs; if resourcemanager is single, keep this value empty |
| 167 | +yarn.resourcemanager.ha.rm.ids=192.168.xx.xx,192.168.xx.xx |
| 168 | +# if resourcemanager HA is enabled or not use resourcemanager, please keep the default value; |
| 169 | +# If resourcemanager is single, you only need to replace ds1 to actual resourcemanager hostname |
| 170 | +yarn.application.status.address=http://localhost:%s/ds/v1/cluster/apps/%s |
| 171 | +# job history status url when application number threshold is reached(default 10000, maybe it was set to 1000) |
| 172 | +yarn.job.history.status.address=http://localhost:19888/ds/v1/history/mapreduce/jobs/%s |
| 173 | +
|
| 174 | +# datasource encryption enable |
| 175 | +datasource.encryption.enable=false |
| 176 | +
|
| 177 | +# datasource encryption salt |
| 178 | +datasource.encryption.salt=!@#$%^&* |
| 179 | +
|
| 180 | +# data quality jar directory path, it would auto discovery data quality jar from this given dir. You should keep it empty if you do not change anything in |
| 181 | +# data-quality, it will auto discovery by dolphinscheduler itself. Change it only if you want to use your own data-quality jar and it is not in worker-server |
| 182 | +# libs directory(but may sure your jar name start with `dolphinscheduler-data-quality`). |
| 183 | +data-quality.jar.dir= |
| 184 | +
|
| 185 | +#data-quality.error.output.path=/tmp/data-quality-error-data |
| 186 | +
|
| 187 | +# Network IP gets priority, default inner outer |
| 188 | +
|
| 189 | +# Whether hive SQL is executed in the same session |
| 190 | +support.hive.oneSession=false |
| 191 | +
|
| 192 | +# use sudo or not, if set true, executing user is tenant user and deploy user needs sudo permissions; |
| 193 | +# if set false, executing user is the deploy user and doesn't need sudo permissions |
| 194 | +sudo.enable=true |
| 195 | +
|
| 196 | +# network interface preferred like eth0, default: empty |
| 197 | +#dolphin.scheduler.network.interface.preferred= |
| 198 | +
|
| 199 | +# network IP gets priority, default: inner outer |
| 200 | +#dolphin.scheduler.network.priority.strategy=default |
| 201 | +
|
| 202 | +# system env path |
| 203 | +#dolphinscheduler.env.path=env/dolphinscheduler_env.sh |
| 204 | +
|
| 205 | +# development state |
| 206 | +development.state=false |
| 207 | +
|
| 208 | +# rpc port |
| 209 | +alert.rpc.port=50052 |
| 210 | +
|
| 211 | +# way to collect applicationId: log(original regex match), aop |
| 212 | +appId.collect: log |
| 213 | +``` |
| 214 | + |
| 215 | +> **注意**: |
| 216 | +> |
| 217 | +> - 如果只配置了 `api-server/conf/common.properties` 的文件,则只是开启了资源上传的操作,并不能满足正常使用。如果想要在工作流中执行相关文件则需要额外配置 `worker-server/conf/common.properties`。 |
| 218 | +> - 如果用到资源上传的功能,那么[安装部署](https://dolphinscheduler.apache.org/zh-cn/docs/3.2.1/guide/installation//zh-cn/docs/3.2.1/guide/installation/standalone)中,部署用户需要有这部分的操作权限。 |
| 219 | +> - 如果 Hadoop 集群的 NameNode 配置了 HA 的话,需要开启 HDFS 类型的资源上传,同时需要将 Hadoop 集群下的 `core-site.xml` 和 `hdfs-site.xml` 复制到 `worker-server/conf` 以及 `api-server/conf`,非 NameNode HA 跳过次步骤。 |
| 220 | + |
| 221 | +## 3 文件管理 |
| 222 | + |
| 223 | +当在调度过程中需要使用到第三方的 jar 或者用户需要自定义脚本的情况,可以通过在该页面完成相关操作。可创建的文件类型包括:`txt/log/sh/conf/py/java` 等。并且可以对文件进行编辑、重命名、下载和删除等操作。 |
| 224 | + |
| 225 | +> - 当您以`admin`身份登入并操作文件时,需要先给`admin`设置租户 |
| 226 | + |
| 227 | +### 基础操作 |
| 228 | + |
| 229 | +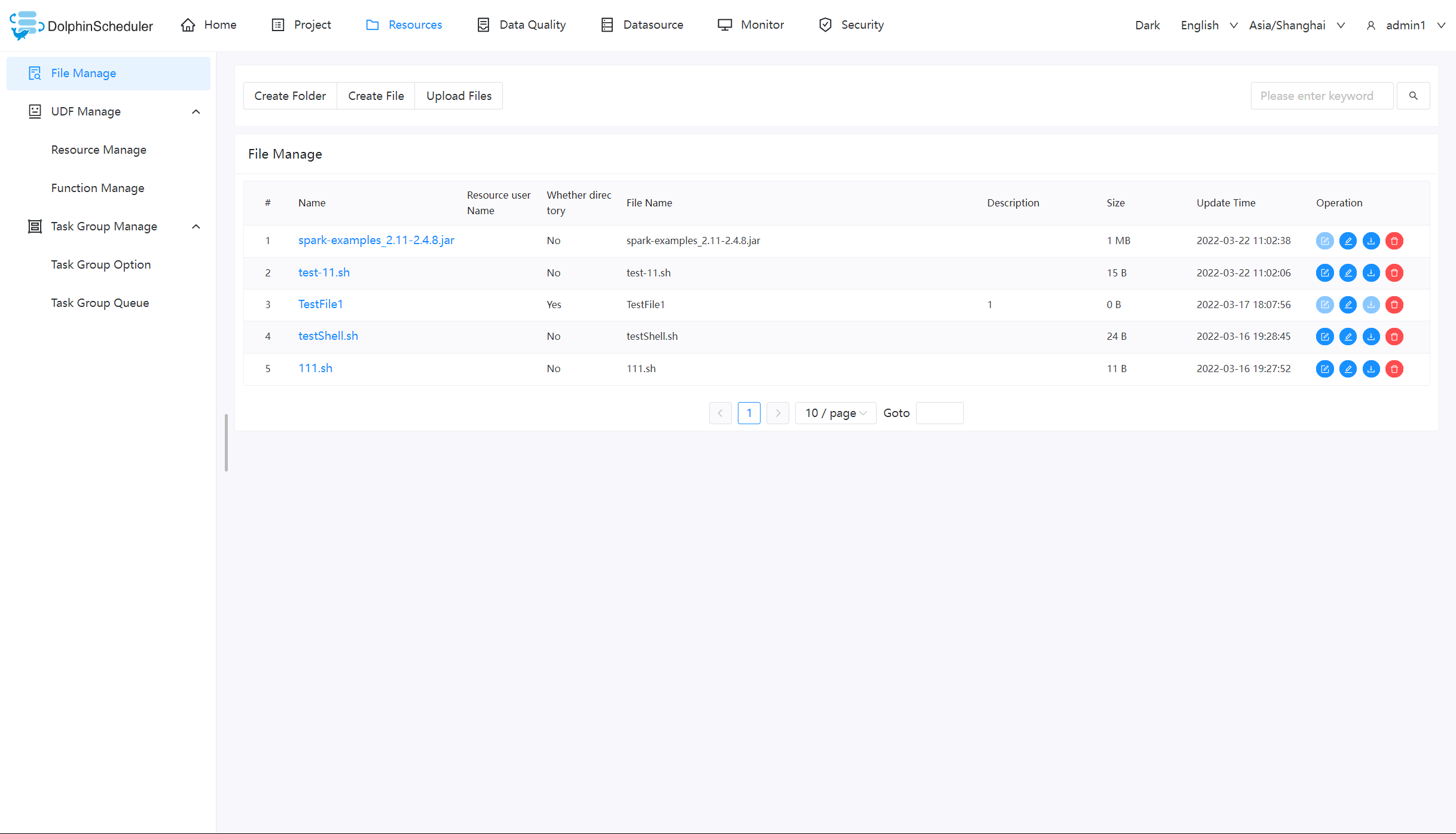 |
| 230 | + |
| 231 | +#### 创建文件 |
| 232 | + |
| 233 | +文件格式支持以下几种类型:txt、log、sh、conf、cfg、py、java、sql、xml、hql、properties |
| 234 | + |
| 235 | +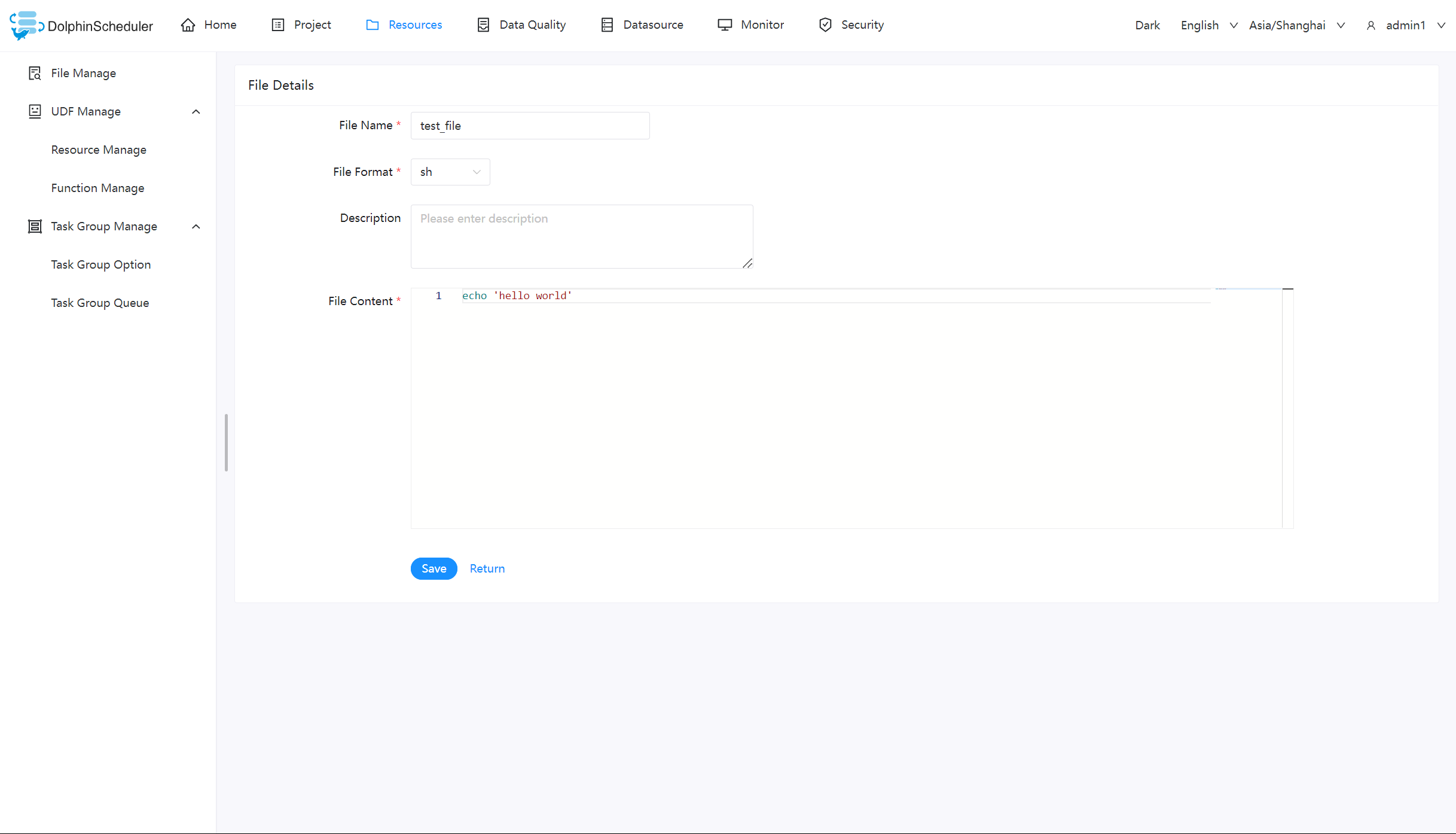 |
| 236 | + |
| 237 | +#### 文件夹创建 |
| 238 | + |
| 239 | + |
| 240 | + |
| 241 | + |
| 242 | + |
| 243 | +#### 上传文件 |
| 244 | + |
| 245 | +上传文件:点击"上传文件"按钮进行上传,将文件拖拽到上传区域,文件名会自动以上传的文件名称补全 |
| 246 | + |
| 247 | +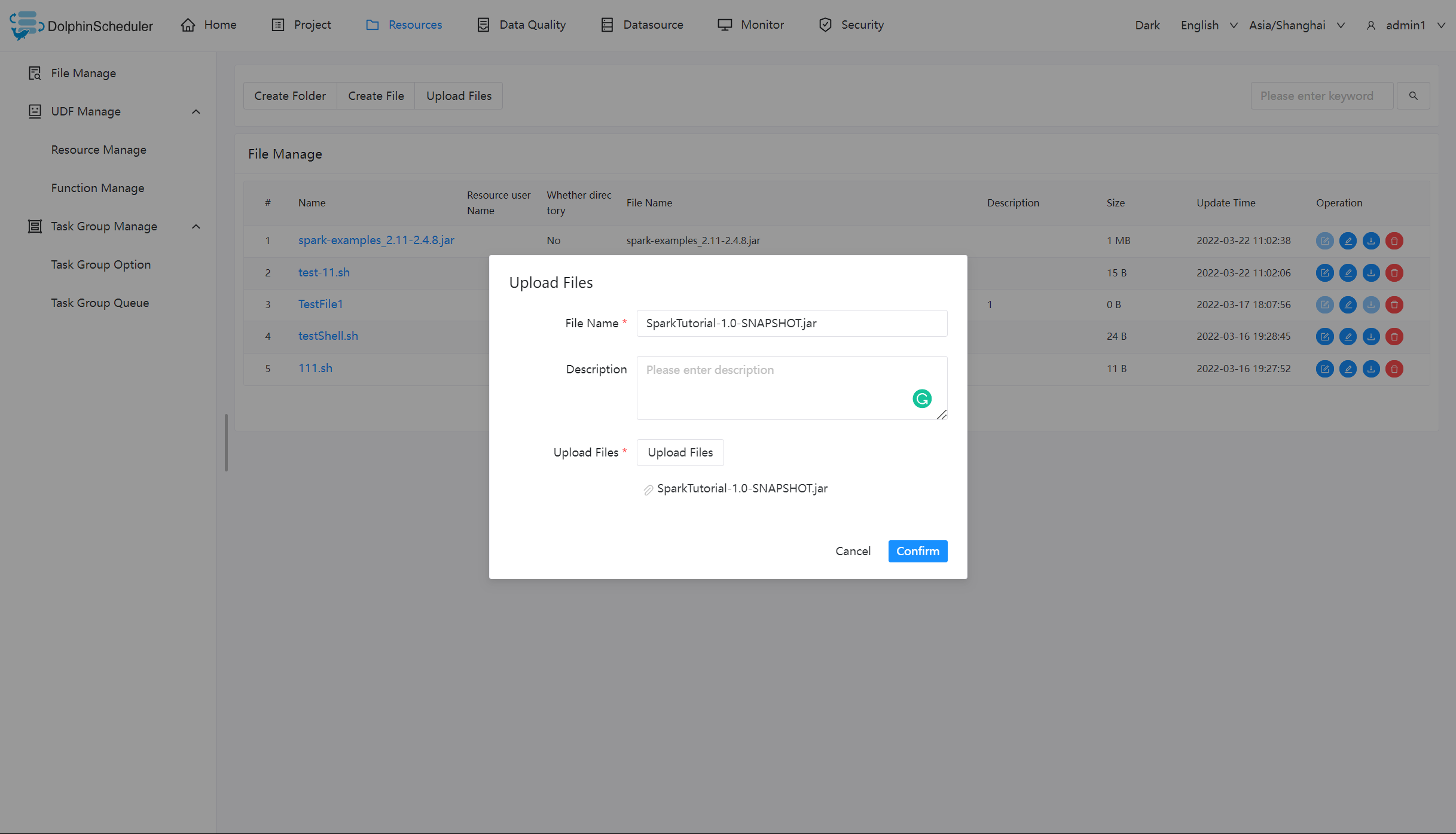 |
| 248 | + |
| 249 | +### 文件查看 |
| 250 | + |
| 251 | +对可查看的文件类型,点击文件名称,可查看文件详情 |
| 252 | + |
| 253 | +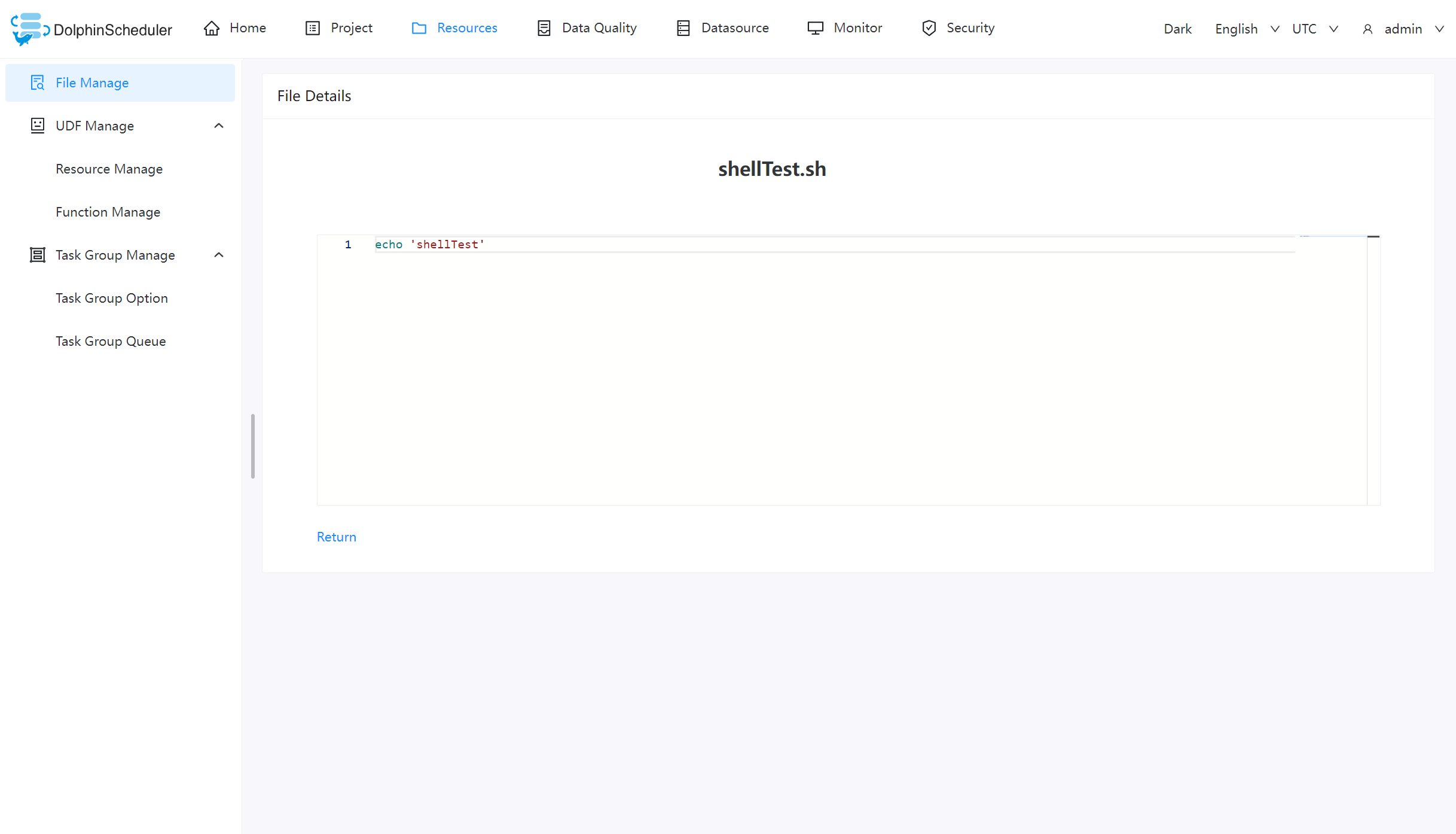 |
| 254 | + |
| 255 | +### 下载文件 |
| 256 | + |
| 257 | +点击文件列表的"下载"按钮下载文件或者在文件详情中点击右上角"下载"按钮下载文件 |
| 258 | + |
| 259 | +### 文件重命名 |
| 260 | + |
| 261 | +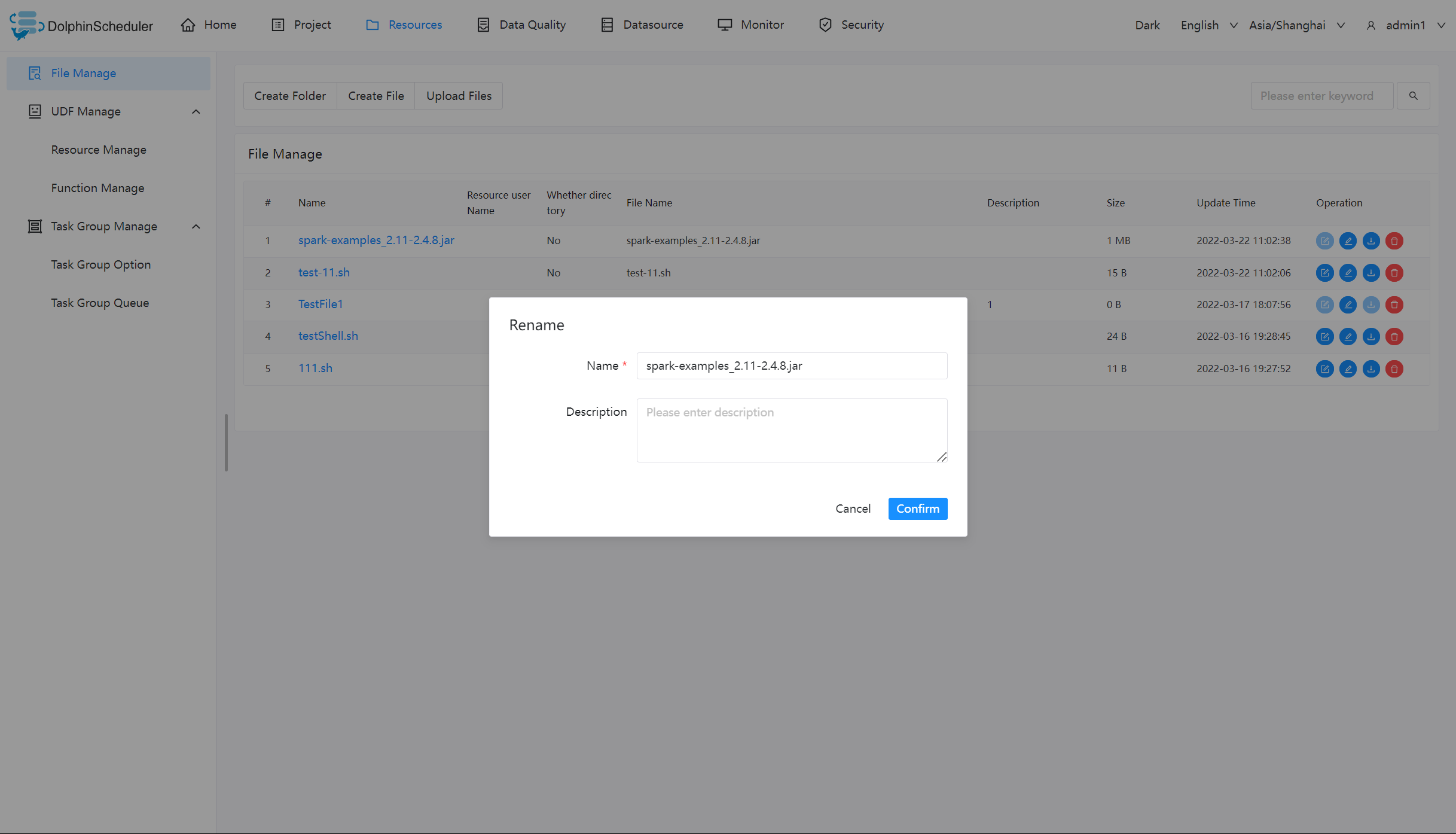 |
| 262 | + |
| 263 | +### 删除文件 |
| 264 | + |
| 265 | +文件列表->点击"删除"按钮,删除指定文件 |
| 266 | + |
| 267 | +### 任务样例 |
| 268 | + |
| 269 | +该样例主要通过一个简单的 shell 脚本,来演示如何在工作流定义中使用资源中心的文件。像 MR、Spark 等任务需要用到 jar 包,也是同理。 |
| 270 | + |
| 271 | +### 创建 shell 文件 |
| 272 | + |
| 273 | +创建一个 shell 文件,输出 “hello world”。 |
| 274 | + |
| 275 | +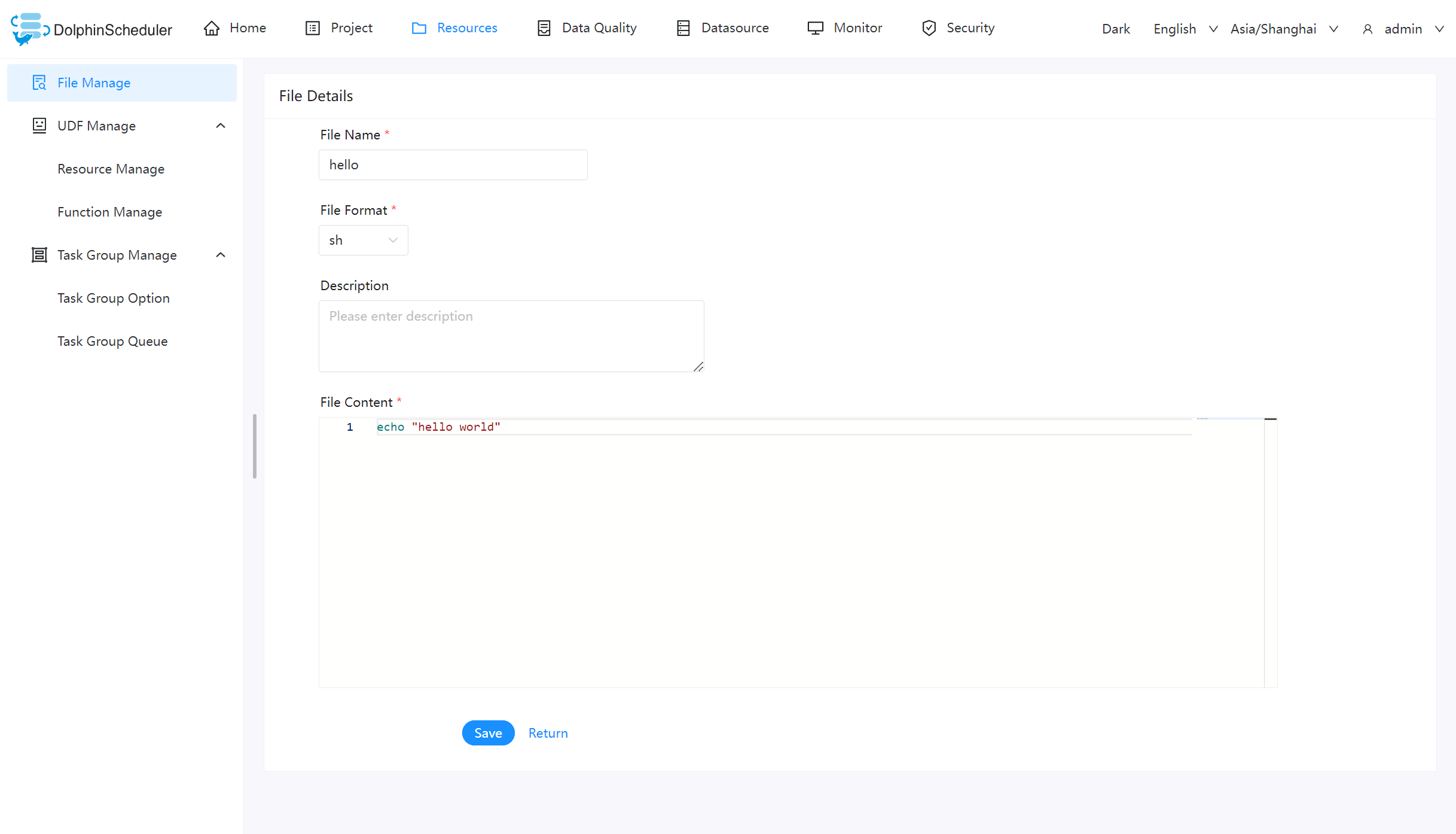 |
| 276 | + |
| 277 | +### 创建工作流执行文件 |
| 278 | + |
| 279 | +在项目管理的工作流定义模块,创建一个新的工作流,使用 shell 任务。 |
| 280 | + |
| 281 | +- 脚本:`sh resource/hello.sh` |
| 282 | +- 资源:选择 `resource/hello.sh` |
| 283 | + |
| 284 | +> 注意:脚本中选择资源文件时文件名称需要保持和所选择资源全路径一致: 例如:资源路径为`resource/hello.sh` 则脚本中调用需要使用`resource/hello.sh`全路径 |
| 285 | + |
| 286 | +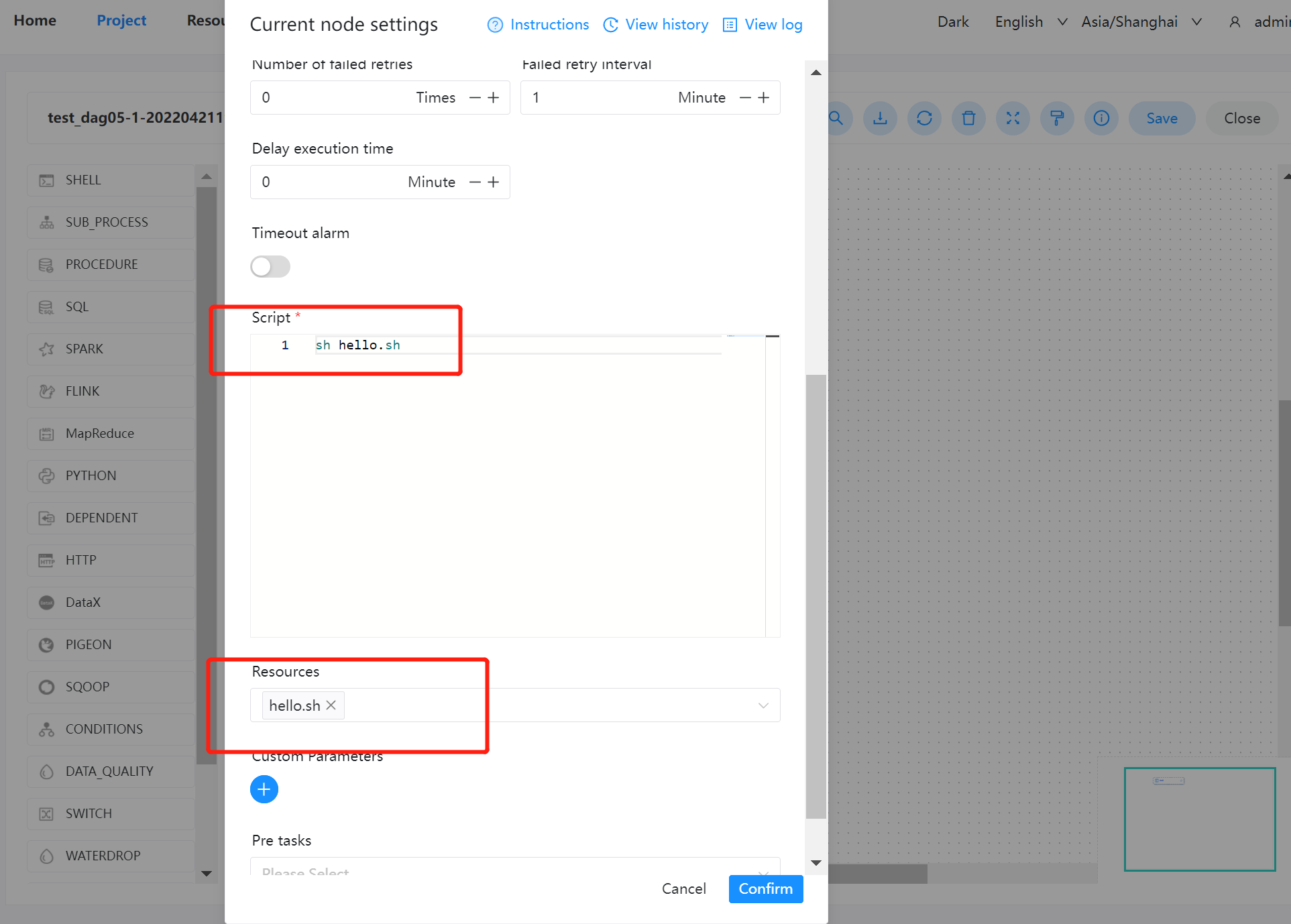 |
| 287 | + |
| 288 | +### 查看结果 |
| 289 | + |
| 290 | +可以在工作流实例中,查看该节点运行的日志结果。如下图: |
| 291 | + |
| 292 | +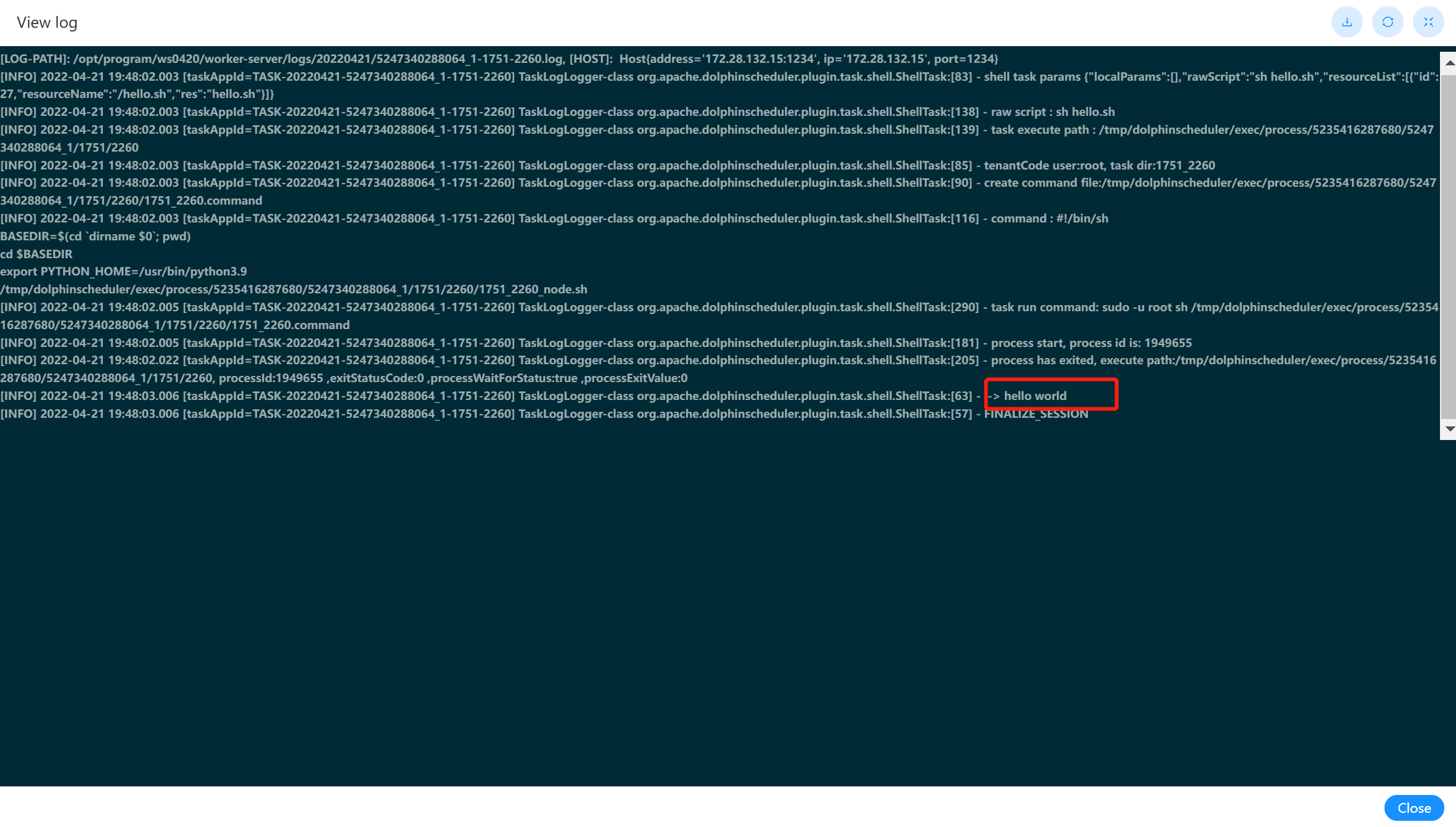 |
| 293 | + |
| 294 | +## 4 工作流实例使用 |
| 295 | + |
| 296 | +这样就能在节点里选用之前创建的资源: |
| 297 | + |
| 298 | + |
| 299 | + |
| 300 | +选择完了后,如何调用呢?注意使用相对路径(毕竟一般资源文件都在 HDFS 上,绝对路径不好写) |
| 301 | + |
| 302 | + |
| 303 | + |
| 304 | +最后观察日志验证即可。 |
0 commit comments