|
| 1 | +# 08-Spark SQL整合Hive |
| 2 | + |
| 3 | +## 0 相关源码 |
| 4 | + |
| 5 | +[sparksql-train](https://github.com/Java-Edge/sparksql-train) |
| 6 | + |
| 7 | +## 1 整合原理及使用 |
| 8 | + |
| 9 | +- Spark,一个快速、可扩展的分布式计算引擎 |
| 10 | +- Hive,一个数据仓库工具,提供数据存储和查询功能 |
| 11 | + |
| 12 | +在 Spark 中用 Hive 可提高数据处理和查询效率。 |
| 13 | + |
| 14 | +### 1.1 场景 |
| 15 | + |
| 16 | +历史原因积累,很多数据原采用Hive处理,现想改用Spark操作,须要求Spark能无缝对接已有的Hive数据,实现平滑过渡。 |
| 17 | + |
| 18 | +### 1.2 MetaStore |
| 19 | + |
| 20 | +Hive底层的元数据信息存储在MySQL,$HIVE_HOME/conf/hive-site.xml |
| 21 | + |
| 22 | + |
| 23 | +Spark若能直接访问MySQL中已有的元数据信息 $SPARK_HOME/conf/hive-site.xml |
| 24 | + |
| 25 | +### 1.3 前置条件 |
| 26 | + |
| 27 | +在使用 Spark 整合 Hive 前,需安装配置: |
| 28 | + |
| 29 | +- Hadoop:数据存储和分布式计算 |
| 30 | +- Hive:数据存储和查询 |
| 31 | +- Spark:分布式计算 |
| 32 | + |
| 33 | +### 1.4 配置Spark连接Hive |
| 34 | + |
| 35 | +在 Spark 中使用 Hive,需将 Hive 的依赖库添加到 Spark 的类路径。在 Java 代码中,可以使用 SparkConf 对象来设置 Spark 应用程序的配置。 |
| 36 | + |
| 37 | +在创建SparkSession时,需要配置Hive支持。这可以通过设置Hive相关的配置参数来实现。 |
| 38 | + |
| 39 | +示例: |
| 40 | + |
| 41 | +```java |
| 42 | +import org.apache.spark.SparkConf; |
| 43 | +import org.apache.spark.sql.SparkSession; |
| 44 | + |
| 45 | +public class SparkHiveIntegration { |
| 46 | + public static void main(String[] args) { |
| 47 | + SparkConf conf = new SparkConf() |
| 48 | + .setAppName("SparkHiveIntegration") |
| 49 | + .setMaster("local[*]") |
| 50 | + // Hive 的元数据存储路径 |
| 51 | + .set("spark.sql.warehouse.dir", "/user/hive/warehouse"); |
| 52 | + |
| 53 | + SparkSession spark = SparkSession.builder() |
| 54 | + .config(conf) |
| 55 | + // 启用了 Hive 支持 |
| 56 | + .enableHiveSupport() |
| 57 | + .getOrCreate(); |
| 58 | + spark.sql("SELECT * FROM mytable").show(); |
| 59 | + spark.stop(); |
| 60 | + } |
| 61 | +} |
| 62 | +``` |
| 63 | + |
| 64 | +Spark SQL 语法与 Hive SQL 语法略不同,参考 Spark SQL 官方文档。 |
| 65 | + |
| 66 | +## 2 ThiriftServer使用 |
| 67 | + |
| 68 | +```bash |
| 69 | +javaedge@JavaEdgedeMac-mini sbin % pwd |
| 70 | +/Users/javaedge/Downloads/soft/spark-2.4.3-bin-2.6.0-cdh5.15.1/sbin |
| 71 | + |
| 72 | +javaedge@JavaEdgedeMac-mini sbin % ./start-thriftserver.sh --master local --jars /Users/javaedge/.m2/repository/mysql/mysql-connector-java/8.0.15/mysql-connector-java-8.0.15.jar |
| 73 | + |
| 74 | +starting org.apache.spark.sql.hive.thriftserver.HiveThriftServer2, logging to /Users/javaedge/Downloads/soft/spark-2.4.3-bin-2.6.0-cdh5.15.1/logs/spark-javaedge-org.apache.spark.sql.hive.thriftserver.HiveThriftServer2-1-JavaEdgedeMac-mini.local.out |
| 75 | +``` |
| 76 | + |
| 77 | +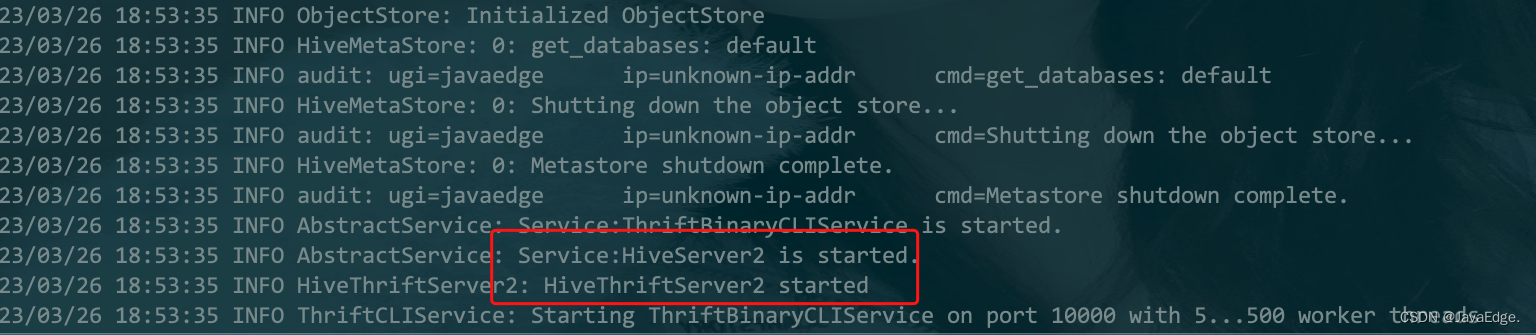 |
| 78 | + |
| 79 | +### beeline |
| 80 | + |
| 81 | +内置了一个客户端工具: |
| 82 | + |
| 83 | +```bash |
| 84 | +javaedge@JavaEdgedeMac-mini bin % ./beeline -u jdbc:hive2://localhost:10000 |
| 85 | +Connecting to jdbc:hive2://localhost:10000 |
| 86 | +log4j:WARN No appenders could be found for logger (org.apache.hive.jdbc.Utils). |
| 87 | +log4j:WARN Please initialize the log4j system properly. |
| 88 | +log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info. |
| 89 | +Connected to: Spark SQL (version 2.4.3) |
| 90 | +Driver: Hive JDBC (version 1.2.1.spark2) |
| 91 | +Transaction isolation: TRANSACTION_REPEATABLE_READ |
| 92 | +Beeline version 1.2.1.spark2 by Apache Hive |
| 93 | +0: jdbc:hive2://localhost:10000> |
| 94 | +``` |
| 95 | + |
| 96 | +当你执行一条命令后: |
| 97 | + |
| 98 | +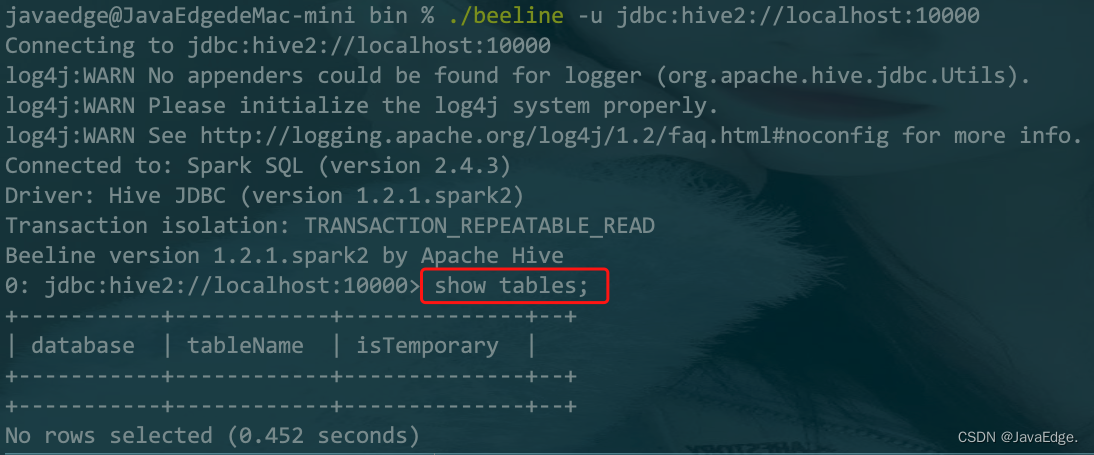 |
| 99 | + |
| 100 | +就能在 [Web UI](http://localhost:4040/sqlserver/) 看到该命令记录: |
| 101 | + |
| 102 | + |
| 103 | + |
| 104 | +## 3 通过代码访问数据 |
| 105 | + |
| 106 | +手敲命令行太慢,更多是代码访问: |
| 107 | + |
| 108 | +```scala |
| 109 | +package com.javaedge.bigdata.cp06 |
| 110 | + |
| 111 | +import java.sql.{Connection, DriverManager, PreparedStatement, ResultSet} |
| 112 | + |
| 113 | +object JDBCClientApp { |
| 114 | + |
| 115 | + def main(args: Array[String]): Unit = { |
| 116 | + Class.forName("org.apache.hive.jdbc.HiveDriver") |
| 117 | + |
| 118 | + val conn: Connection = DriverManager.getConnection("jdbc:hive2://localhost:10000") |
| 119 | + val pstmt: PreparedStatement = conn.prepareStatement("show tables") |
| 120 | + |
| 121 | + val rs: ResultSet = pstmt.executeQuery() |
| 122 | + |
| 123 | + while (rs.next()) { |
| 124 | + // 每行结果集中第一列和第二列的数据,即表名和其他信息,以字符串形式输出到控制台 |
| 125 | + println(rs.getObject(1) + " : " + rs.getObject(2)) |
| 126 | + } |
| 127 | + } |
| 128 | +} |
| 129 | +``` |
| 130 | + |
| 131 | +最后打成 jar 包,扔到服务器定时运行即可执行作业啦。 |
| 132 | + |
| 133 | +### 3.1 ThiriftServer V.S Spark Application 例行作业 |
| 134 | + |
| 135 | +Thrift Server 独立的服务器应用程序,允许多个客户端通过网络协议访问其上运行的 Thrift 服务。Thrift 服务通常是由一组 Thrift 定义文件定义的,这些文件描述了可以从客户端发送到服务器的请求和响应消息的数据结构和协议。Thrift Server 可以使用各种编程语言进行开发,包括 Java、C++、Python 等,并支持多种传输和序列化格式,例如 TSocket、TFramedTransport、TBinaryProtocol 等。使用 Thrift Server,你可以轻松地创建高性能、可伸缩和跨平台的分布式应用程序。 |
| 136 | + |
| 137 | +Spark Application,基于 Apache Spark 的应用程序,它使用 Spark 编写的 API 和库来处理大规模数据集。Spark Application 可以部署在本地计算机或云环境中,并且支持各种数据源和格式,如 Hadoop 分布式文件系统(HDFS)、Apache Cassandra、Apache Kafka 等。Spark Application 可以并行处理数据集,以加快数据处理速度,并提供了广泛的机器学习算法和图形处理功能。使用 Spark Application,你可以轻松地处理海量数据,提取有价值的信息和洞察,并帮助你做出更明智的业务决策。 |
| 138 | + |
| 139 | +因此,Thrift Server 和 Spark Application 适用不同的场景和应用程序: |
| 140 | + |
| 141 | +- 需要创建一个分布式服务并为多个客户端提供接口,使用 Thrift Server |
| 142 | +- 需要处理大规模数据集并使用分布式计算和机器学习算法来分析数据,使用 Spark Application |
| 143 | + |
| 144 | +## 4 Spark 代码访问 Hive 数据 |
| 145 | + |
| 146 | +### 4.1 执行Hive查询 |
| 147 | + |
| 148 | +如何在Spark中使用Spark SQL执行Hive查询呢? |
| 149 | + |
| 150 | +通过SparkSession对象执行Hive查询。可以使用Spark SQL的语法来执行Hive的SQL语句。示例代码如下: |
| 151 | + |
| 152 | +```scala |
| 153 | +// 查询Hive中的表 |
| 154 | +spark.sql("SHOW TABLES").show() |
| 155 | + |
| 156 | +// 执行其他Hive SQL语句 |
| 157 | +spark.sql("SELECT * FROM table_name").show() |
| 158 | +``` |
| 159 | + |
| 160 | +## 5 Spark SQL 函数实战 |
| 161 | + |
| 162 | +### 5.0 parallelize |
| 163 | + |
| 164 | +SparkContext的一个方法,将一个本地数据集转为RDD。parallelize方法接受一个集合作为输入参数,并根据指定并行度创建一个新RDD。 |
| 165 | + |
| 166 | +语法: |
| 167 | + |
| 168 | +```scala |
| 169 | +// data表示要转换为 RDD 的本地集合 |
| 170 | +// numSlices表示 RDD 的分区数,通常等于集群中可用的 CPU 核心数量。 |
| 171 | +val rdd = |
| 172 | +sc.parallelize(data, numSlices) |
| 173 | +``` |
| 174 | + |
| 175 | +将一个包含整数值的本地数组转换为RDD: |
| 176 | + |
| 177 | +```scala |
| 178 | +package com.javaedge.bigdata.cp06 |
| 179 | + |
| 180 | +import org.apache.spark.{SparkConf, SparkContext} |
| 181 | + |
| 182 | +object DemoClientApp { |
| 183 | + |
| 184 | + def main(args: Array[String]): Unit = { |
| 185 | + |
| 186 | + // 创建 SparkConf 对象 |
| 187 | + val conf = new SparkConf().setAppName("ParallelizeExample").setMaster("local[*]") |
| 188 | + |
| 189 | + // 创建 SparkContext 对象 |
| 190 | + val sc = new SparkContext(conf) |
| 191 | + |
| 192 | + // 定义本地序列 |
| 193 | + val data = Seq(1, 2, 3, 4, 5) |
| 194 | + |
| 195 | + // 使用 parallelize 方法创建 RDD |
| 196 | + val rdd = sc.parallelize(data) |
| 197 | + |
| 198 | + // 执行转换操作 |
| 199 | + val result = rdd.map(_ * 2) |
| 200 | + |
| 201 | + // 显示输出结果 |
| 202 | + result.foreach(println) |
| 203 | + } |
| 204 | +} |
| 205 | + |
| 206 | +output: |
| 207 | +4 |
| 208 | +2 |
| 209 | +6 |
| 210 | +10 |
| 211 | +8 |
| 212 | +``` |
| 213 | + |
| 214 | +创建了一个包含整数值的本地序列 `data`,然后使用 `parallelize` 方法将其转换为一个 RDD。接下来,我们对 RDD 进行转换操作,并打印输出结果。 |
| 215 | + |
| 216 | +使用 `parallelize` 方法时,请确保正确配置 Spark 应用程序,并设置正确 CPU 核心数量和内存大小。否则,可能会导致应用程序性能下降或崩溃。 |
| 217 | + |
| 218 | +### 5.1 内置函数 |
| 219 | + |
| 220 | +都在这: |
| 221 | + |
| 222 | + |
| 223 | + |
| 224 | +#### 统计 PV、UV 实例 |
| 225 | + |
| 226 | +```scala |
| 227 | +package com.javaedge.bigdata.chapter06 |
| 228 | + |
| 229 | +import org.apache.spark.rdd.RDD |
| 230 | +import org.apache.spark.sql.{DataFrame, SparkSession} |
| 231 | + |
| 232 | +/** |
| 233 | + * 内置函数 |
| 234 | + */ |
| 235 | +object BuiltFunctionApp { |
| 236 | + |
| 237 | + def main(args: Array[String]): Unit = { |
| 238 | + |
| 239 | + |
| 240 | + val spark: SparkSession = SparkSession.builder() |
| 241 | + .master("local").appName("HiveSourceApp") |
| 242 | + .getOrCreate() |
| 243 | + |
| 244 | + // day userid |
| 245 | + val userAccessLog = Array( |
| 246 | + "2016-10-01,1122", |
| 247 | + "2016-10-01,1122", |
| 248 | + "2016-10-01,1123", |
| 249 | + "2016-10-01,1124", |
| 250 | + "2016-10-01,1124", |
| 251 | + "2016-10-02,1122", |
| 252 | + "2016-10-02,1121", |
| 253 | + "2016-10-02,1123", |
| 254 | + "2016-10-02,1123" |
| 255 | + ) |
| 256 | + |
| 257 | + import spark.implicits._ |
| 258 | + |
| 259 | + // Array ==> RDD |
| 260 | + val userAccessRDD: RDD[String] = spark.sparkContext.parallelize(userAccessLog) |
| 261 | + |
| 262 | + val userAccessDF: DataFrame = userAccessRDD.map(x => { |
| 263 | + val splits: Array[String] = x.split(",") |
| 264 | + Log(splits(0), splits(1).toInt) |
| 265 | + }).toDF |
| 266 | + |
| 267 | + userAccessDF.show() |
| 268 | + |
| 269 | + import org.apache.spark.sql.functions._ |
| 270 | + |
| 271 | + // select day, count(user_id) from xxx group by day; |
| 272 | + userAccessDF.groupBy("day").agg(count("userId").as("pv")).show() |
| 273 | + |
| 274 | + userAccessDF.groupBy("day").agg(countDistinct("userId").as("uv")).show() |
| 275 | + spark.stop() |
| 276 | + } |
| 277 | + |
| 278 | + private case class Log(day: String, userId: Int) |
| 279 | +} |
| 280 | +``` |
| 281 | + |
| 282 | +### 5.2 自定义函数 |
| 283 | + |
| 284 | +```scala |
| 285 | +package com.javaedge.bigdata.chapter06 |
| 286 | + |
| 287 | +import org.apache.spark.rdd.RDD |
| 288 | +import org.apache.spark.sql.{DataFrame, SparkSession} |
| 289 | + |
| 290 | + |
| 291 | +/** |
| 292 | + * 统计每个人爱好的个数 |
| 293 | + * pk:3 |
| 294 | + * jepson: 2 |
| 295 | + * |
| 296 | + * |
| 297 | + * 1)定义函数 |
| 298 | + * 2)注册函数 |
| 299 | + * 3)使用函数 |
| 300 | + */ |
| 301 | +object UDFFunctionApp { |
| 302 | + def main(args: Array[String]): Unit = { |
| 303 | + |
| 304 | + val spark: SparkSession = SparkSession.builder() |
| 305 | + .master("local").appName("HiveSourceApp") |
| 306 | + .getOrCreate() |
| 307 | + |
| 308 | + |
| 309 | + import spark.implicits._ |
| 310 | + |
| 311 | + val infoRDD: RDD[String] = spark.sparkContext.textFile( |
| 312 | + "/Users/javaedge/Downloads/sparksql-train/data/hobbies.txt") |
| 313 | + val infoDF: DataFrame = infoRDD.map(_.split("###")).map(x => { |
| 314 | + Hobbies(x(0), x(1)) |
| 315 | + }).toDF |
| 316 | + |
| 317 | + infoDF.show(false) |
| 318 | + |
| 319 | + // TODO... 定义函数 和 注册函数 |
| 320 | + spark.udf.register("hobby_num", (s: String) => s.split(",").size) |
| 321 | + |
| 322 | + infoDF.createOrReplaceTempView("hobbies") |
| 323 | + |
| 324 | + //TODO... 函数的使用 |
| 325 | + spark.sql("select name, hobbies, hobby_num(hobbies) as hobby_count from hobbies").show(false) |
| 326 | + |
| 327 | + // select name, hobby_num(hobbies) from xxx |
| 328 | + |
| 329 | + spark.stop() |
| 330 | + } |
| 331 | + |
| 332 | + private case class Hobbies(name: String, hobbies: String) |
| 333 | +} |
| 334 | + |
| 335 | +output: |
| 336 | ++------+----------------------+ |
| 337 | +|name |hobbies | |
| 338 | ++------+----------------------+ |
| 339 | +|pk |jogging,Coding,cooking| |
| 340 | +|jepson|travel,dance | |
| 341 | ++------+----------------------+ |
| 342 | + |
| 343 | ++------+----------------------+-----------+ |
| 344 | +|name |hobbies |hobby_count| |
| 345 | ++------+----------------------+-----------+ |
| 346 | +|pk |jogging,Coding,cooking|3 | |
| 347 | +|jepson|travel,dance |2 | |
| 348 | ++------+----------------------+-----------+ |
| 349 | +``` |
| 350 | + |
| 351 | +## 6 总结 |
| 352 | + |
| 353 | +通过上述示例代码,可以看到如何在 Java 中使用 Spark 整合 Hive。通过使用 Hive 的数据存储和查询功能,可以在 Spark 中高效地处理和分析数据。当然,还有许多其他功能和配置可以使用,例如设置 Spark 应用程序的资源分配、数据分区、数据格式转换等。 |
0 commit comments