|
| 1 | +# 查询执行引擎:如何让聚合计算加速? |
| 2 | + |
| 3 | +计算引擎在海量数据查询下的一些优化策略,包括: |
| 4 | + |
| 5 | +- 计算下推 |
| 6 | +- 更复杂的并行执行框架 |
| 7 | + |
| 8 | +这些策略对应了从查询请求输入到查询计划这个阶段的工作。那么,整体查询任务的下一个阶段就是查询计划的执行,承担这部分工作的组件一般称为查询执行引擎。 |
| 9 | + |
| 10 | +单从架构层面看,查询执行引擎与分布式架构无关,但是由于分布式数据库要面对海量数据,所以对提升查询性能相比单体数据库有更强烈的诉求,更关注这部分的优化。 |
| 11 | + |
| 12 | +你是不是碰到过这样的情况,对宽口径数据做聚合计算时,系统要等待很长时间才能给出结果。那是因为这种情况涉及大量数据参与,常常会碰到查询执行引擎的短板。你肯定想知道,有优化办法吗? |
| 13 | + |
| 14 | +当然是有的。查询执行引擎是否高效与其采用的模型有直接关系,模型主要有三种:火山模型、向量化模型和代码生成。你碰到的情况很可能是没用对模型。 |
| 15 | + |
| 16 | +## 1 火山模型(Volcano Model) |
| 17 | + |
| 18 | +也称迭代模型(Iterator Model),最著名的查询执行模型,早在1990年就在论文“[Volcano, an Extensible and Parallel Query Evaluation System](https://core.ac.uk/download/pdf/54846488.pdf)”提出。主流OLTP数据库Oracle、MySQL都采用这模型。 |
| 19 | + |
| 20 | +一个查询计划会被分解为多个代数运算符(Operator)。每个Operator是一个迭代器,都要实现一个next()接口,通常包括三步: |
| 21 | + |
| 22 | +1. 调用子节点Operator的next()接口,获取一个元组(Tuple) |
| 23 | +2. 对元组执行Operator特定的处理 |
| 24 | +3. 返回处理后的元组 |
| 25 | + |
| 26 | +通过火山模型,查询执行引擎可以优雅地将任意Operator组装在一起,而不需要考虑每个Operator的具体处理逻辑。查询执行时会由查询树自顶向下嵌套调用next()接口,数据则自底向上地被拉取处理。所以,这种处理方式也称为拉取执行模型(Pull Based)。 |
| 27 | + |
| 28 | +为更好理解火山模型的拉取执行过程,看聚合计算例子,来自Databricks的[一篇文章](https://databricks.com/blog/2016/05/23/apache-spark-as-a-compiler-joining-a-billion-rows-per-second-on-a-laptop.html)(Sameer Agarwal et al. (2016))。 |
| 29 | + |
| 30 | +```sql |
| 31 | +select count(*) from store_sales where ss_item_sk = 1000; |
| 32 | +``` |
| 33 | + |
| 34 | + |
| 35 | + |
| 36 | +开始从扫描运算符TableScan获取数据,通过过滤运算符Filter开始推动元组的处理。然后,过滤运算符传递符合条件的元组到聚合运算符Aggregate。 |
| 37 | + |
| 38 | +你可能对“元组”这个词有点陌生,其实它大致就是指数据记录(Record),因为讨论算法时学术文献中普遍会使用元组这个词,为了让你更好地与其他资料衔接起来,我们这里就沿用“元组”这个词。 |
| 39 | + |
| 40 | +优点是处理逻辑清晰,每个Operator 只要关心自己的处理逻辑即可,耦合性低。但是它的缺点也非常明显,主要是两点: |
| 41 | + |
| 42 | +1. 虚函数调用次数过多,造成CPU资源的浪费。 |
| 43 | +2. 数据以行为单位进行处理,不利于发挥现代CPU的特性。 |
| 44 | + |
| 45 | +### 1.1 问题分析 |
| 46 | + |
| 47 | +啥是虚函数?火山模型中,处理一个元组最少需调用一次next(),next()就是虚函数。这些函数的调用由编译器通过虚函数调度实现;虽虚函数调度是现代计算机体系结构中重点优化部分,但仍需消耗很多CPU指令,相当慢。 |
| 48 | + |
| 49 | +第二个缺点是没发挥现代CPU特性。 |
| 50 | + |
| 51 | +#### 1.1.1 CPU寄存器和内存 |
| 52 | + |
| 53 | +在火山模型中,每次一个算子给另外一个算子传递元组,都要将这个元组存放在内存,18讲说过,以行为组织单位易带来CPU缓存失效。 |
| 54 | + |
| 55 | +#### 1.1.2 循环展开(Loop unrolling) |
| 56 | + |
| 57 | +运行简单循环,现代编译器和CPU非常高效。编译器会自动展开简单循环,甚至在每个CPU指令中产生单指令多数据流(SIMD)指令来处理多个元组。 |
| 58 | + |
| 59 | +#### 1.1.3 单指令多数据流(SIMD) |
| 60 | + |
| 61 | +SIMD 指令可在同一CPU时钟周期内,对同列的不同数据执行相同指令。这些数据会加载到SIMD 寄存器。 |
| 62 | + |
| 63 | +Intel 编译器配置了 AVX-512(高级矢量扩展)指令集,SIMD 寄存器达到 512 比特,即可并行运算 16 个 4 字节整数。 |
| 64 | + |
| 65 | +过去20年火山模型都运行很好,主要因为这一时期执行过程瓶颈是磁盘I/O。而现代数据库大量使用内存,读取效率大幅提升,CPU成新瓶颈。因此,现在对火山模型所有优化和改进都是围绕着提升CPU运行效率。 |
| 66 | + |
| 67 | +### 改良方法(运算符融合) |
| 68 | + |
| 69 | +要对火山模型进行优化,一个最简单的方法就是减少执行过程中Operator的函数调用。比如,通常来说Project和Filter都是常见的Operator,在很多查询计划中都会出现。OceanBase1.0就将两个Operator融合到了其它的Operator中。这样做有两个好处: |
| 70 | + |
| 71 | +1. 降低了整个查询计划中Operator的数量,也就简化了Operator间的嵌套调用关系,最终减少了虚函数调用次数。 |
| 72 | +2. 单个Operator的处理逻辑更集中,增强了代码局部性能力,更容易发挥CPU的分支预测能力。 |
| 73 | + |
| 74 | +#### 分支预测能力 |
| 75 | + |
| 76 | +你可能还不了解什么是分支预测能力,我这里简单解释一下。 |
| 77 | + |
| 78 | +分支预测是指CPU执行跳转指令时的一种优化技术。当出现程序分支时CPU需要执行跳转指令,在跳转的目的地址之前无法确定下一条指令,就只能让流水线等待,这就降低了CPU效率。为了提高效率,设计者在CPU中引入了一组寄存器,用来专门记录最近几次某个地址的跳转指令。 |
| 79 | + |
| 80 | +这样,当下次执行到这个跳转指令时,就可以直接取出上次保存的指令,放入流水线。等到真正获取到指令时,如果证明取错了则推翻当前流水线中的指令,执行真正的指令。 |
| 81 | + |
| 82 | +这样即使出现分支也能保持较好的处理效率,但是寄存器的大小总是有限的,所以总的来说还是要控制程序分支,分支越少流水线效率就越高。 |
| 83 | + |
| 84 | +刚刚说的运算符融合是一种针对性的优化方法,优点是实现简便而且快速见效,但进一步的提升空间很有限。 |
| 85 | + |
| 86 | +因此,学术界还有更积极改进思路: |
| 87 | + |
| 88 | +- 优化现有的迭代模型,每次返回一批数据而非一个元组,向量化模型(Vectorization) |
| 89 | +- 从根本上消除迭代计算的性能损耗,代码生成(Code Generation) |
| 90 | + |
| 91 | +## 2 向量化:TiDB&CockroachDB |
| 92 | + |
| 93 | +向量化模型最早提出是在[MonerDB-X100(Vectorwise)](http://cs.brown.edu/courses/cs227/archives/2008/Papers/ColumnStores/MonetDB.pdf)系统,已成为现代硬件条件下广泛使用的两种高效查询引擎之一。 |
| 94 | + |
| 95 | +向量化模型与火山模型的最大差异就是,其中的Operator是向量化运算符,是基于列来重写查询处理算法的。所以简单来说,向量化模型是由一系列支持向量化运算的Operator组成的执行模型。 |
| 96 | + |
| 97 | +向量化模型处理聚合计算: |
| 98 | + |
| 99 | + |
| 100 | + |
| 101 | +通过这个执行过程可以发现,向量化模型依然采用了拉取式模型。它和火山模型的唯一区别就是Operator的next()函数每次返回的是一个向量块,而不是一个元组。向量块是访问数据的基本单元,由固定的一组向量组成,这些向量和列 / 字段有一一对应的关系。 |
| 102 | + |
| 103 | +向量处理背后的主要思想是,按列组织数据和计算,充分利用 CPU,把从多列到元组的转化推迟到较晚的时候执行。这种方法在不同的操作符间平摊了函数调用的开销。 |
| 104 | + |
| 105 | +向量化模型首先在OLAP数据库中采用,与列式存储搭配使用可以获得更好的效果,例如ClickHouse。 |
| 106 | + |
| 107 | +我们课程里定义的分布式数据库都是面向OLTP场景的,所以不能直接使用列式存储,但是可以采用折中的方式来实现向量化模型,也就是在底层的Operator中完成多行到向量块的转化,上层的Operator都是以向量块作为输入。这样改造后,即使是与行式存储结合,仍然能够显著提升性能。在TiDB和CockroachDB的实践中,性能提升可以达到数倍,甚至数十倍。 |
| 108 | + |
| 109 | +### 向量化运算符示例 |
| 110 | + |
| 111 | +我们以Hash Join为例,来看下向量化模型的执行情况。 |
| 112 | + |
| 113 | +20介绍过Hash Join的执行逻辑,就是两表关联时,以Inner表的数据构建Hash表,然后以Outer表中的每行记录,分别去Hash表查找。 |
| 114 | + |
| 115 | +``` |
| 116 | +Class HashJoin |
| 117 | + Primitives probeHash_, compareKeys_, bulidGather_; |
| 118 | + ... |
| 119 | +int HashJoin::next() |
| 120 | + //消费构建侧的数据构造Hash表,代码省略 |
| 121 | + ... |
| 122 | + //获取探测侧的元组 |
| 123 | + int n = probe->next() |
| 124 | + //计算Hash值 |
| 125 | + vec<int> hashes = probeHash_.eval(n) |
| 126 | + //找到Hash匹配的候选元组 |
| 127 | + vec<Entry*> candidates = ht.findCandidates(hashes) |
| 128 | + vec<Entry*, int> matches = {} |
| 129 | + //检测是否匹配 |
| 130 | + while(candidates.size() > 0) |
| 131 | + vec<bool> isEqual = compareKeys_.eval(n, candidates) |
| 132 | + hits, candidates = extractHits(isEqual, candidates) |
| 133 | + matches += hits |
| 134 | + //从Hash表收集数据为下个Operator缓存 |
| 135 | + buildGather_.eval(matches) |
| 136 | + return matches.size() |
| 137 | +``` |
| 138 | + |
| 139 | +我们可以看到这段处理逻辑中的变量都是Vector,还有事先定义一些专门处理Vector的元语(Primitives)。 |
| 140 | + |
| 141 | +总的来说,向量化执行模型对火山模型做了针对性优化,在以下几方面有明显改善: |
| 142 | + |
| 143 | +1. 减少虚函数调用数量,提高了分支预测准确性; |
| 144 | +2. 以向量块为单位处理数据,利用CPU的数据预取特性,提高了CPU缓存命中率; |
| 145 | +3. 多行并发处理,发挥了CPU的并发执行和SIMD特性。 |
| 146 | + |
| 147 | +## 3 代码生成:OceanBase |
| 148 | + |
| 149 | +另一种高效查询执行引擎,这名听着奇怪,但确实没有更好翻译。代码生成全称是以数据为中心的代码生成(Data-Centric Code Generation),也称编译执行(Compilation)。 |
| 150 | + |
| 151 | +在解释“代码生成”前,我们先来分析一下手写代码和通用性代码的执行效率问题。我们还是继续使用讲火山模型时提到的例子,将其中Filter算子的实现逻辑表述如下: |
| 152 | + |
| 153 | +```java |
| 154 | +class Filter(child: Operator, predicate: (Row => Boolean)) |
| 155 | + extends Operator { |
| 156 | + def next(): Row = { |
| 157 | + var current = child.next() |
| 158 | + while (current == null || predicate(current)) { |
| 159 | + current = child.next() |
| 160 | + } |
| 161 | + return current |
| 162 | + } |
| 163 | +} |
| 164 | +``` |
| 165 | + |
| 166 | +如专门对这操作编写代码(手写代码),那么大致是下面这样: |
| 167 | + |
| 168 | +```js |
| 169 | +var count = 0 |
| 170 | +for (ss_item_sk in store_sales) { |
| 171 | + if (ss_item_sk == 1000) { |
| 172 | + count += 1 |
| 173 | + } |
| 174 | +} |
| 175 | +``` |
| 176 | + |
| 177 | +在两种执行方式中,手写代码显然没有通用性,但Databricks的工程师对比了两者的执行效率,测试显示手工代码的吞吐能力要明显优于火山模型。 |
| 178 | + |
| 179 | + |
| 180 | + |
| 181 | +手工编写代码的执行效率之所以高,就是因为它的循环次数要远远小于火山模型。而代码生成就是按照一定的策略,通过即时编译(JIT)生成代码可以达到类似手写代码的效果。 |
| 182 | + |
| 183 | +代码生成是一个推送执行模型(Push Based),这也有助于解决火山模型嵌套调用虚函数过多的问题。与拉取模型相反,推送模型自底向上地执行,执行逻辑的起点直接就在最底层Operator,其处理完一个元组之后,再传给上层Operator继续处理。 |
| 184 | + |
| 185 | +Hyper是一个深入使用代码生成技术的数据库,[Hyper实现的论文](https://www.vldb.org/pvldb/vol4/p539-neumann.pdf)(Thomas Neumann (2011))中有一个例子,我这里引用过来帮助你理解它的执行过程。 |
| 186 | + |
| 187 | +要执行的查询语句是这样的: |
| 188 | + |
| 189 | +```sql |
| 190 | +select * from R1,R3, |
| 191 | +(select R2.z,count(*) |
| 192 | + from R2 |
| 193 | + where R2.y=3 |
| 194 | + group by R2.z) R2 |
| 195 | +where R1.x=7 and R1.a=R3.b and R2.z=R3.c |
| 196 | +``` |
| 197 | + |
| 198 | +SQL解析后会得到一棵查询树,就是下图的左侧的样子,我们可以找到R1、R2和R3对应的是三个分支。 |
| 199 | + |
| 200 | + |
| 201 | + |
| 202 | +要获得最优的CPU执行效率,就要使数据尽量不离开CPU的寄存器,这样就可以在一个CPU流水线(Pipeline)上完成数据的处理。但是,查询计划中的Join操作要生成Hash表加载到内存中,这个动作使数据必须离开寄存器,称为物化(Materilaize)。所以整个执行过程会被物化操作分隔为4个Pipeline。而像Join这种会导致物化操作的Operator,在论文称为Pipeline-breaker。 |
| 203 | + |
| 204 | +通过即时编译生成代码得到对应Piepline的四个代码段,可以表示为下面的伪码: |
| 205 | + |
| 206 | + |
| 207 | + |
| 208 | +代码生成消除了火山模型中的大量虚函数调用,让大部分指令可以直接从寄存器取数,极大地提高了CPU的执行效率。 |
| 209 | + |
| 210 | +代码生成的基本逻辑清楚了,但它的工程实现还是挺复杂的,所以会有不同粒度的划分。比如,如果是整个查询计划的粒度,就会称为整体代码生成(Whole-Stage Code Generation),这个难度最大;相对容易些的是代码生成应用于表达式求值(Expression Evaluation),也称为表达式代码生成。在OceanBase 2.0版本中就实现了表达式代码生成。 |
| 211 | + |
| 212 | +如果你想再深入了解代码生成的相关技术,就需要有更全面的编译器方面的知识做基础,比如你可以学习宫文学老师的编译原理课程。 |
| 213 | + |
| 214 | +## 4 总结 |
| 215 | + |
| 216 | +1. 火山模型自1990年提出后,是长期流行的查询执行模型,至今仍在Oracle、MySQL中使用。但面对海量数据时,火山模型有CPU使用率低的问题,性能有待提升。 |
| 217 | +2. 火山模型仍有一些优化空间,比如运算符融合,可以适度减少虚函数调用,但提升空间有限。学术界提出的两种优化方案是向量化和代码生成。 |
| 218 | +3. 简单来说,向量化模型就是一系列向量化运算符组成的执行模型。向量化模型首先在OLAP数据库和大数据领域广泛使用,配合列式存储取得很好的效果。虽然OLTP数据库的场景不适于列式存储,但将其与行式存储结合也取得了明显的性能提升。 |
| 219 | +4. 代码生成是现代编译器与CPU结合的产物,也可以大幅提升查询执行效率。代码生成的基础逻辑是,针对性的代码在执行效率上必然优于通用运算符嵌套。代码生成根据算法会被划分成多个在Pipeline执行的单元,提升CPU效率。代码生成有不同的粒度,包括整体代码生成和表达式代码生成,粒度越大实现难度越大。 |
| 220 | + |
| 221 | +向量化和代码生成是两种高效查询模型,并没有最先出现在分布式数据库领域,反而是在OLAP数据库和大数据计算领域得到了更广泛的实践。ClickHouse和Spark都同时混用了代码生成和向量化模型这两项技术。目前TiDB和CockroachDB都应用向量化模型,查询性能得到了一个数量级的提升。OceanBase中则应用了代码生成技术优化了表达式运算。 |
| 222 | + |
| 223 | +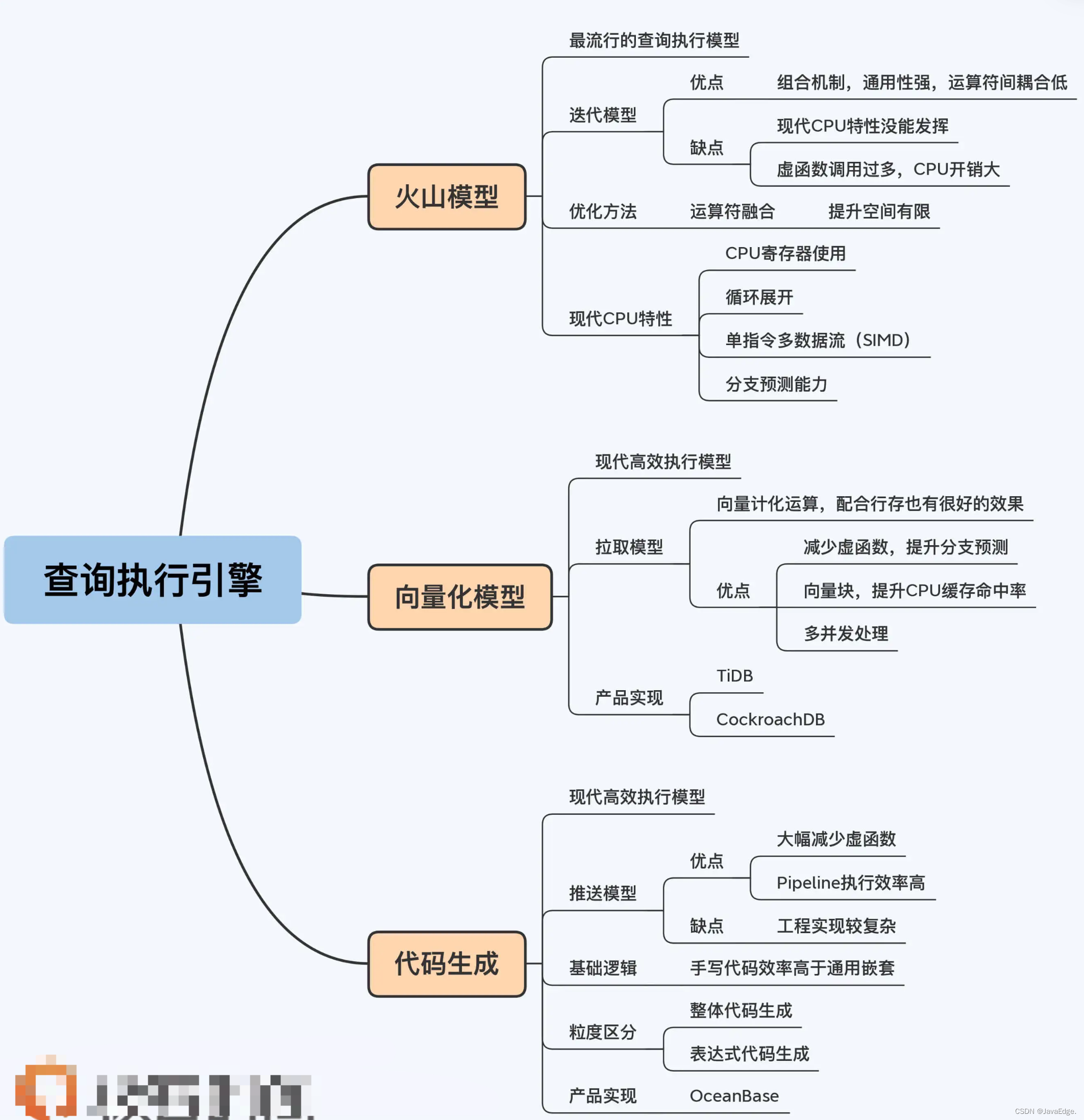 |
| 224 | + |
| 225 | +## 5 FAQ |
| 226 | + |
| 227 | +主要讨论了查询执行引擎的优化,核心是如何最大程度发挥现代CPU的特性。其实,这也是基础软件演进中一个普遍规律,每当硬件技术取得突破后就会引发软件的革新。那么,我的问题就是你了解的基础软件中,哪些产品分享了硬件技术变革红利? |
| 228 | + |
| 229 | +参考 |
| 230 | + |
| 231 | +- Goetz Graefe: [*Volcano, an Extensible and Parallel Query Evaluation System*](https://core.ac.uk/download/pdf/54846488.pdf) |
| 232 | +- Peter Boncz et al.: [*MonetDB/X100: Hyper-Pipelining Query Execution*](http://cs.brown.edu/courses/cs227/archives/2008/Papers/ColumnStores/MonetDB.pdf) |
| 233 | +- Sameer Agarwal et al.: [*Apache Spark as a Compiler: Joining a Billion Rows per Second on a Laptop*](https://databricks.com/blog/2016/05/23/apache-spark-as-a-compiler-joining-a-billion-rows-per-second-on-a-laptop.html) |
| 234 | +- Thomas Neumann: [*Efficiently Compiling Efficient Query Plans for Modern Hardware*](https://www.vldb.org/pvldb/vol4/p539-neumann.pdf) |
| 235 | + |
| 236 | + |
| 237 | + |
| 238 | +代码生成==编译器运行期优化: |
| 239 | + |
| 240 | +- 针对循环做优化 |
| 241 | +- 减少过程调用开销 |
| 242 | +- 对控制流做优化 |
| 243 | +- 向量计算 |
0 commit comments