This is the official repository for Demystifying Video Reasoning.
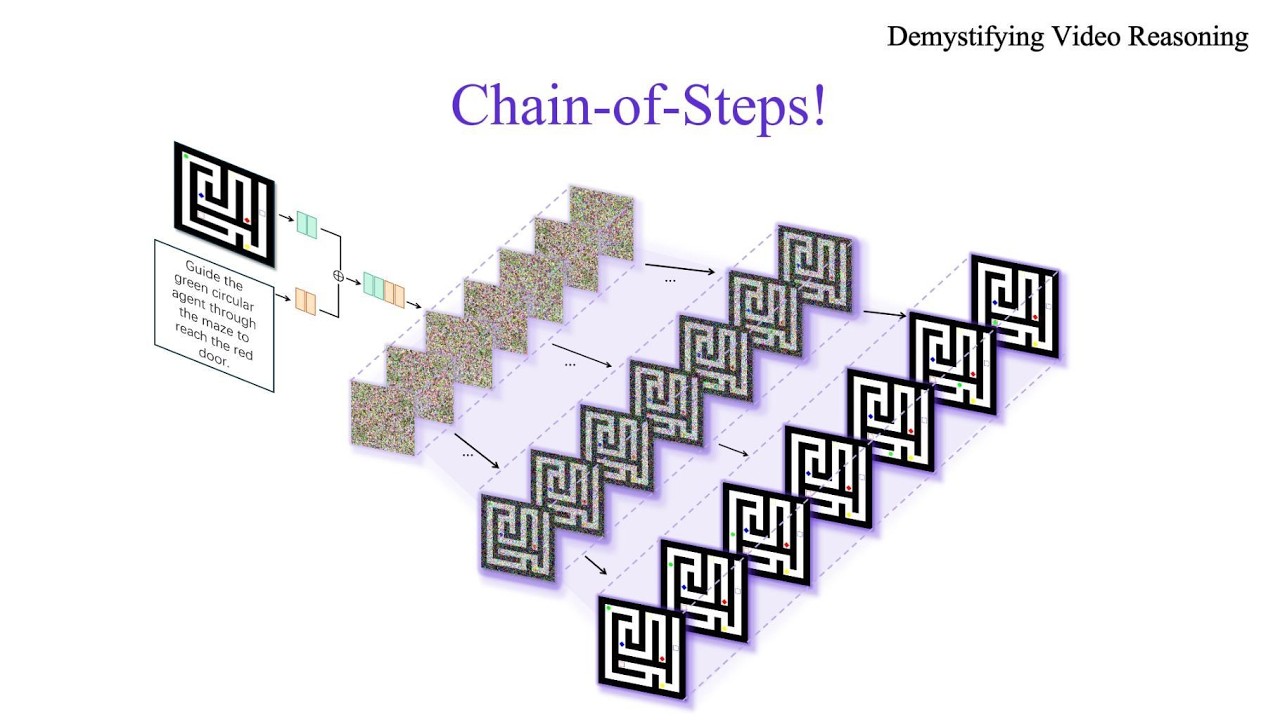
Recent advances in video generation have revealed an unexpected phenomenon: diffusion-based video models exhibit non-trivial reasoning capabilities. Prior work attributes this to a Chain-of-Frames (CoF) mechanism, where reasoning is assumed to unfold sequentially across video frames. In this work, we challenge this assumption and uncover a fundamentally different mechanism. We show that reasoning in video models instead primarily emerges along the diffusion denoising steps. Through qualitative analysis and targeted probing experiments, we find that models explore multiple candidate solutions in early denoising steps and progressively converge to a final answer, a process we term Chain-of-Steps (CoS). Beyond this core mechanism, we identify several emergent reasoning behaviors critical to model performance: (1) working memory, enabling persistent reference; (2) self-correction and enhancement, allowing recovery from incorrect intermediate solutions; and (3) perception before action, where early steps establish semantic grounding and later steps perform structured manipulation. During a diffusion step, we further uncover self-evolved functional specialization within Diffusion Transformers, where early layers encode dense perceptual structure, middle layers execute reasoning, and later layers consolidate latent representations. Motivated by these insights, we present a simple training-free strategy as a proof-of-concept, demonstrating how reasoning can be improved by ensembling latent trajectories from identical models with different random seeds. Overall, our work provides a systematic understanding of how reasoning emerges in video generation models, offering a foundation to guide future research in better exploiting the inherent reasoning dynamics of video models as a new substrate for intelligence.
- [2026-04-15] Tools for intermediate step decoding and layer-wise token-level visualization are released.
- [2026-03-20] We have released the paper Demystifying Video Reasoning.
- Intermediate steps decoding tool
- Layer-wise token-Level visualization tool
pip install -e .
pip install matplotlib scikit-learn # for token visualizationDownload from Hugging Face:
huggingface-cli download Wan-AI/Wan2.2-I2V-A14B --local-dir ./models/Wan-AI/Wan2.2-I2V-A14BDownload from Hugging Face:
huggingface-cli download Wan-AI/Wan2.1-I2V-14B-720P --local-dir ./models/Wan-AI/Wan2.1-I2V-14B-720PDownload from Hugging Face:
huggingface-cli download DiffSynth-Studio/LTX-2.3-Repackage --local-dir ./models/DiffSynth-Studio/LTX-2.3-Repackage
huggingface-cli download google/gemma-3-12b-it-qat-q4_0-unquantized --local-dir ./models/google/gemma-3-12b-it-qat-q4_0-unquantizedNote: Models are also auto-downloaded at runtime if not found locally.
VBVR lora model family trained on VBVR-Dataset
Download VBVR-Wan2.2 from Hugging Face, VBVR-Wan2.1 from Hugging Face, VBVR-LTX2.3 from Hugging Face:
huggingface-cli download Video-Reason/VBVR-Wan2.1-diffsynth --local-dir ./models/VBVR/VBVR-Wan2.1-diffsynth
huggingface-cli download Video-Reason/VBVR-Wan2.2-diffsynth --local-dir ./models/VBVR/VBVR-Wan2.2-diffsynth
huggingface-cli download Video-Reason/VBVR-LTX2.3-diffsynth --local-dir ./models/VBVR/VBVR-LTX2.3-diffsynthDownload the VBVR-Bench evaluation data from Hugging Face:
huggingface-cli download Video-Reason/VBVR-Bench-Data --repo-type dataset --local-dir ./data/VBVR-BenchThe evaluation data has the following structure:
data/VBVR-Bench/
├── In-Domain_50/
│ ├── G-xxx_task_name_data-generator/
│ │ ├── 00000/
│ │ │ ├── first_frame.png
│ │ │ ├── final_frame.png
│ │ │ ├── ground_truth.mp4
│ │ │ └── prompt.txt
│ │ ├── 00001/
│ │ └── ...
│ └── ...
└── Out-of-Domain_50/
└── ...
Saves intermediate video snapshots at selected denoising steps, showing how generation evolves from noise to the final output. Automatically processes all splits and tasks in VBVR-Bench.
# Wan2.2 base model
python tools/step_visualization.py \
--model wan2.2 \
--eval_root ./data/VBVR-Bench \
--output_root ./output/step_viz/wan2.2
# Wan2.2 with LoRA
python tools/step_visualization.py \
--model wan2.2 \
--high_noise_lora_path ./models/VBVR/VBVR-Wan2.2-diffsynth/high_noise_lora.safetensors \
--low_noise_lora_path ./models/VBVR/VBVR-Wan2.2-diffsynth/low_noise_lora.safetensors \
--eval_root ./data/VBVR-Bench \
--output_root ./output/step_viz/wan2.2_lora
# Wan2.1 base model
python tools/step_visualization.py \
--model wan2.1 \
--eval_root ./data/VBVR-Bench \
--output_root ./output/step_viz/wan2.1
# Wan2.1 with LoRA
python tools/step_visualization.py \
--model wan2.1 \
--lora_path ./models/VBVR/VBVR-Wan2.1-diffsynth/lora.safetensors \
--eval_root ./data/VBVR-Bench \
--output_root ./output/step_viz/wan2.1_lora
# LTX2.3
python tools/step_visualization.py \
--model ltx2.3 \
--eval_root ./data/VBVR-Bench \
--output_root ./output/step_viz/ltx2.3 \
--num_inference_steps 40
# LTX2.3 with LoRA
python tools/step_visualization.py \
--model ltx2.3 \
--lora_path ./models/VBVR/VBVR-LTX2.3-diffsynth/lora.safetensors \
--eval_root ./data/VBVR-Bench \
--output_root ./output/step_viz/ltx2.3_lora \
--num_inference_steps 40Hooks into DiT transformer blocks to capture hidden states, producing spatial heatmaps, PCA maps, temporal energy curves, and cross-step summary plots. Automatically processes all splits and tasks in VBVR-Bench.
python tools/token_visualization.py \
--model wan2.2 \
--eval_root ./data/VBVR-Bench \
--output_root ./output/token_viz/wan2.2 \
--layers 0 10 20 30 39 \
--max_samples 5Run step visualization on a single image + text prompt (no VBVR-Bench data needed):
python tools/custom_step_visualization.py \
--model wan2.2 \
--image ./my_image.png \
--prompt "A cat walks across the room" \
--output_dir ./output/custom_step \
--num_frames 81Run token-level feature map visualization on a single image + text prompt (no VBVR-Bench data needed):
python tools/custom_token_visualization.py \
--model wan2.2 \
--image ./my_image.png \
--prompt "A cat walks across the room" \
--output_dir ./output/custom_token \
--num_frames 81 \
--layers 0 10 20 30 39| Argument | Description | Default |
|---|---|---|
--model |
Model family: wan2.2, wan2.1, ltx2.3 |
required |
--lora_path |
LoRA weights (wan2.1 / ltx2.3) | None |
--high_noise_lora_path |
High-noise DiT LoRA (wan2.2) | None |
--low_noise_lora_path |
Low-noise DiT LoRA (wan2.2) | None |
--lora_alpha |
LoRA merge alpha | 1.0 |
--num_inference_steps |
Denoising steps | 50 |
--seed |
Random seed | 1 |
--vis_steps |
Steps to visualize: all or 0-19,45-49 |
all |
--max_samples |
Max samples per task (bench tools) | None (all) |
@article{wang2026demystifing,
title={Demystifing Video Reasoning},
author={Wang, Ruisi and Cai, Zhongang and Pu, Fanyi and Xu, Junxiang and Yin, Wanqi and Wang, Maijunxian and Ji, Ran and Gu, Chenyang and Li, Bo and Huang, Ziqi and Deng, Hokin and Lin, Dahua and Liu, Ziwei and Yang, Lei},
journal={arXiv preprint arXiv:2603.16870},
year={2026}
}This project includes code that is modified from the original work by the DiffSynth-Studio team.
- Source repository: https://github.com/modelscope/DiffSynth-Studio
- Original project: modelscope/DiffSynth-Studio
We gratefully acknowledge the authors and contributors of DiffSynth-Studio for their work. Please refer to the original repository for full details, updates, and licensing information.