This is a checkers (or draughts) game with several AI opponent algorithms. It is written in Rust and uses some cuBLAS/CUDA.
Rules: English draughts
# Clone the repository:
git clone git@github.com:rreemmii-dev/Checkers-AI.git
cd Checkers-AIEnsure you have cargo installed.
Several features are available:
There are several neural network implementations available, each using a different tool. If no specific implementation is chosen, a default one is provided. If multiple implementations are selected, the implementation at the bottom of the list takes precedence:
openblas: Uses OpenBLAS, a BLAS that runs on CPUs.cublas: Uses CUDA and cuBLAS, a BLAS that runs on NVIDIA GPUs.
The neural network uses f32 precision by default.
To use f64 precision, enable the f64_precision feature.
Three commands are available:
play: Play against the AI.train: Train the AI.tournament: Run a tournament between different AI versions.
Once the features and the command have been chosen, run the program.
For example, to use the f64_precision feature and the play command:
cargo run --release --features f64_precision playCurrently, there are two AI algorithms, both of which utilize a negamax search with alpha-beta pruning.
They differ in how their heuristic is defined:
- The first one uses a human-made heuristic.
- The second one uses a neural-network-based heuristic.
The AI operates in two stages:
-
A shallow multithreaded depth-first search (DFS) where the AI explores 2 moves deep.
-
At the end of each branch of the initial DFS, a negamax search with alpha-beta pruning is run. Each negamax search runs in a different thread.
Since the negamax exploration has limited depth, a method is needed to compute the score of a board. This is done using either a human-made heuristic or a neural-network-based heuristic.
First, a score is assigned to each piece. This score depends on the piece type (man or king) and its position on the board. For example, men near the promotion line and kings near the center of the board are considered more valuable.
Then, a coefficient is chosen to represent how close the game is to ending in a draw (either by 3 repetitions, or by playing 2 * 40 moves without capture or promotion). A coefficient of 50 (out of 100) reduces the effective scores by half, bringing them closer to a draw.
However, the AI's performance relies heavily on the arbitrary choices made when defining this heuristic. Thus, the next approach uses a neural network to try to eliminate this arbitrary component.
The goal is to create an AI with as little human knowledge as possible. Ideally, it would have no prior knowledge other than the rules of checkers. Thus, the human-made heuristic is ultimately replaced by a neural network to compute board scores.
A multilayer perceptron is used. Its input is an array of 130 values: 4 values * 32 squares to identify which piece, if any, is in each square, plus 1 value for the number of moves since the last capture and 1 value for the number of repetitions. Its output is a score between 0 and 1, where a higher score is better for the current player.
Everything related to the mathematical background of the neural network can be found in the Appendix#Neural network maths.
There is no supervised learning: the bot learns entirely by playing against itself.
Currently, 8 different neural networks are playing against each other and learning from these games. Since choosing the learning rate is difficult, an evolutionary algorithm is used. There are 3 groups, each with a different learning rate. After a period of time (from 15min to 1h), the best group among the 3 is selected. The winning group is cloned into 3 new groups, each with the exact same neural network weights but slightly different learning rates (lower than, equal to and higher than the winning learning rate).
The neural network outputs a value between 0 and 1, that represents the probability of the move leading to a winning configuration. Usually, this value is given to the search algorithm, which looks for the highest score.
However, during the training phase, suboptimal moves should be allowed, as they may eventually lead to a better board configuration. Thus, once each probability is converted to a score using the logit function, a softmax function determines the next move.
To analyze how the neural networks improve over time, the tournament command (cf #Getting started#Choose command) runs a round-robin tournament: each neural network plays against every other neural network.
A graph is generated that plots the number of wins, draws, and losses for each neural network, both while playing as white and as black.
Here is an example of the two resulting graphs:
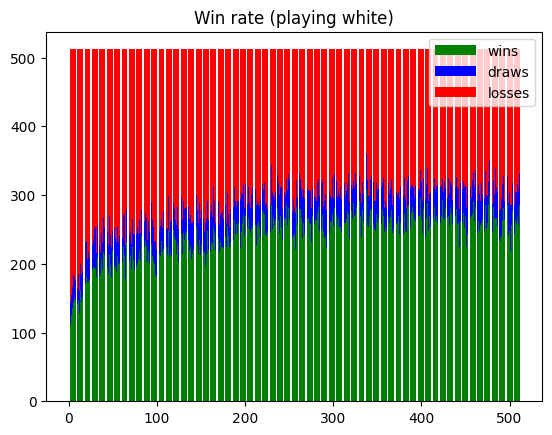
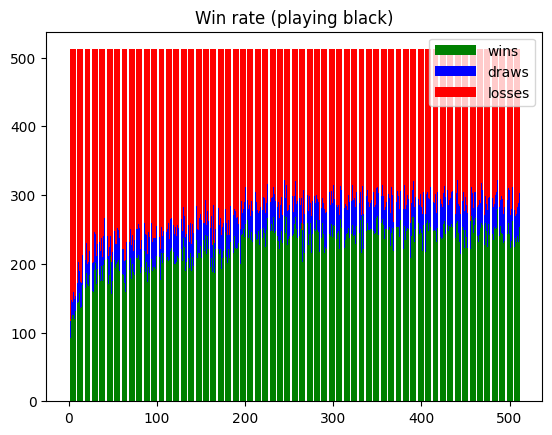
Here is a comparison featuring the 100 most recent neural networks, each playing against the human-based heuristic:
Each player had a limited amount of time (100ms) to explore as deeply as possible.
| Neural-network | Win | Draw | Loss |
|---|---|---|---|
| Playing as white | 2% | 19% | 79% |
| Playing as black | 1% | 16% | 83% |
Each player had an unlimited amount of time to explore up to a given depth (4 moves ahead).
| Neural-network | Win | Draw | Loss |
|---|---|---|---|
| Playing as white | 100% | 0% | 0% |
| Playing as black | 1% | 39% | 60% |
As of today, the neural-network-based heuristics underperform compared to the human-based heuristic. Although the neural-network-based heuristics provide a better board evaluation than the human-based heuristic especially when playing as white (overall win in the depth-limited comparison), every heuristic computation takes more time due to the overhead of the neural network. Thus, the human-based heuristic can explore deeper in the same amount of time, leading to its overall win in the time-limited comparison.
Distributed under the MIT License. See LICENSE.md.
Here are some ideas for future improvements. Keep in mind that these are just ideas and may not result in any improvements.
- Use a Monte Carlo tree search instead of alpha-beta pruning
- Use 3 boards instead of 4 for the neural network input: is_white, is_black, is_king
- Improve the human-made heuristic by solving simple positions (eg: <= 3-4 pieces per player)
- Store neural networks in a binary file instead of a text file. There should still be a way to display neural networks for humans to read
Bitboards are a way to avoid iterating over each square, for example, when searching for possible moves.
3 bitboards are enough to store the whole board: one for white pieces, one for black pieces and one for both white and black kings.
There is a total of 32 squares, each having a different index:
| 7 | 28 | 29 | 30 | 31 | ||||
|---|---|---|---|---|---|---|---|---|
| 6 | 24 | 25 | 26 | 27 | ||||
| 5 | 20 | 21 | 22 | 23 | ||||
| 4 | 16 | 17 | 18 | 19 | ||||
| 3 | 12 | 13 | 14 | 15 | ||||
| 2 | 8 | 9 | 10 | 11 | ||||
| 1 | 4 | 5 | 6 | 7 | ||||
| 0 | 0 | 1 | 2 | 3 | ||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
Here are the gradient and derivative calculations used in the neural network.
For more details, see https://medium.com/@waadlingaadil/learn-to-build-a-neural-network-from-scratch-yes-really-cac4ca457efc
Layer values:
Weights:
$W_l \in \mathcal{M}{n_l, n{l - 1}}$
Biases:
Expected (= real) result:
Guessed result:
Cost:
$\frac{\partial A_l}{\partial Z_l} = (1_{i = j} \cdot A_l(i) \cdot (1 - A_l(i)))_{i, j}$
$\frac{\partial Z_l}{\partial A_{l - 1}} = W_l$
$\frac{\partial Z_l^T}{\partial W_l^T} = A_l^T$
$\frac{\partial Z_l}{\partial B_l} = I_{n_l}$